2008 디지털제어산업기사 최종합격!

'Computer Science' 카테고리의 다른 글
| 대용량 데이터베이스 조회관련 (0) | 2008.11.26 |
|---|---|
| Web Spider 구현하기 (0) | 2008.11.24 |
| 2008 디지털제어산업기사 최종발표 (0) | 2008.11.10 |
| 메모리 DC를 이용한 더블 버퍼링 (0) | 2008.10.21 |
| directshow(다이렉트쇼)프로그래밍 (0) | 2008.10.19 |
2008 디지털제어산업기사 최종합격!
| 대용량 데이터베이스 조회관련 (0) | 2008.11.26 |
|---|---|
| Web Spider 구현하기 (0) | 2008.11.24 |
| 2008 디지털제어산업기사 최종발표 (0) | 2008.11.10 |
| 메모리 DC를 이용한 더블 버퍼링 (0) | 2008.10.21 |
| directshow(다이렉트쇼)프로그래밍 (0) | 2008.10.19 |
| 2008년도 산업기사 제 003회 최종합격자 명단 | ||||||||||||
| 주의ⅰ명단 하단에 '합격인원 00명'이 보이지 않을 경우 반드시 새로고침(F5)을 누르거나 다른 PC에서 확인하시기 바랍니다. | ||||||||||||
| 주의ⅱ동명이인이 있을수 있으니 수험번호를 필히 확인하시기 바랍니다. | ||||||||||||
| 합격자 조회 방법 : 키보드의 Ctrl + F 를 눌러 수험번호 또는 이름을 입력하여 조회하시기 바랍니다. | ||||||||||||
| 디지털제어산업기사(2171) | ||||||||||||
| 수험번호 | 성명 | 수험번호 | 성명 | 수험번호 | 성명 | 수험번호 | 성명 | 수험번호 | 성명 | 수험번호 | 성명 | |
| 01109545 | 이상훈 | 01201896 | 조진호 | 01461033 | 오정주 | 02120396 | 이근배 | 02130473 | 이형연 | 02160333 | 김우현 | |
| 02200521 | 김성준 | 03102127 | 오인식 | 03102519 | 지승화 | 04110975 | 이승록 | 05110411 | 신용희 | 05110413 | 변정주 | |
| 05110417 | 기병국 | 05110420 | 이수창 | 05110423 | 김홍대 | 05110425 | 박종길 | 05150182 | 김영세 | 05150450 | 이시원 | |
| 05160307 | 김현형 | 05160646 | 안원희 | 05201307 | 김종회 | 05201352 | 안치우 | 05202355 | 박종민 | 05202611 | 김용주 | |
| 07100142 | 설금숙 | 07101310 | 김태호 | 08100417 | 김대현 | 08102054 | 백철기 | 08102192 | 남성욱 | 08410048 | 손안세 | |
| 10411069 | 김용현 | 13100545 | 이학수 | 13106585 | 이동석 | 13108344 | 이종찬 | 13108350 | 김진주 | 13108352 | 김현민 | |
| 13108354 | 황보원 | 13108362 | 구세훈 | 13108363 | 한광일 | 13201729 | 박선홍 | 13412012 | 양웅식 | 13412033 | 손성락 | |
| 14100844 | 유현민 | 15170494 | 박현호 | 23042353 | 임재윤 | |||||||
| 합격인원 | ||||||||||||
| Web Spider 구현하기 (0) | 2008.11.24 |
|---|---|
| 2008 디지털제어산업기사 최종합격 (0) | 2008.11.13 |
| 메모리 DC를 이용한 더블 버퍼링 (0) | 2008.10.21 |
| directshow(다이렉트쇼)프로그래밍 (0) | 2008.10.19 |
| [펀글] MFC tip 10 (0) | 2008.09.24 |
화면에 이미지나 도형, 텍스트 등 여러가지를 출력하다 보면 깜박거리는 현상을 보게 된다. 한 번 출력하고 말 것이라면 크게 문제가 안 될 수 있지만 지속적으로 출력하는 상황에서는 깜박거림은 피하고 싶은 문제 중 하나이고 가장 쉽고 일반적인 해결책은 더블 버퍼링이다.
다음은 메모리 DC를 이용한 더블 버퍼링 방법이다.
1. 출력하려는 크기의 비트맵과 메모리 DC를 생성하고 메모리 DC에 생성된 비트맵을 선택한다.
HBITMAP hbmMem = CreateCompatibleBitmap(hdc, 48, 48);
HDC hdcMem = CreateCompatibleDC(hdc);
HBITMAP hbmOld = (HBITMAP)SelectObject(hdcMem, hbmMem);
2. 생성한 메모리 DC(hdcMem)로 그리려는 내용을 출력한다.
3. 메모리 DC의 내용을 출력할 DC로 복사한다.
BitBlt(hdc, 0, 0, 48, 48, hdcMem, 0, 0, SRCCOPY);
4. 메모리 DC와 비트맵을 정리한다.
SelectObject(hdcMem, hbmOld);
DeleteObject(hbmMem);
DeleteDC(hdcMem);
| 2008 디지털제어산업기사 최종합격 (0) | 2008.11.13 |
|---|---|
| 2008 디지털제어산업기사 최종발표 (0) | 2008.11.10 |
| directshow(다이렉트쇼)프로그래밍 (0) | 2008.10.19 |
| [펀글] MFC tip 10 (0) | 2008.09.24 |
| 채터링을 c로 짤려는데 잘안되네여.. (0) | 2008.09.15 |
여기에서는, DirectShow 로 사용되는 기본적인 용어와 개념에 대해 설명한다. 이 내용을 읽으면 처음의 DirectShow 애플리케이션을 생성 할 준비가 갖추어진다.
필터와 필터 그래프
DirectShow 를 구성하는 요소는,"필터" 로 불리는 소프트웨어 구성 요소이다. 필터는, 멀티미디어 스트림에 대해서 어떠한 조작을 실행하는 소프트웨어 구성 요소이다. 예를 들어, DirectShow 의 필터에서는 다음과 같은 조작을 실행할 수 있다.
필터는 입력을 받아, 출력을 생성한다. 예를 들어, 필터가 MPEG-1 비디오를 디코드하는 경우, 입력은 MPEG 로 encode 된 스트림이며, 출력은 일련의 압축되지 않은 비디오 프레임이다.
DirectShow 에서는, 필터 체인을 접속해, 어느 필터로부터의 출력을 다른 필터의 입력으로 하는 것에 의해, 애플리케이션은 모든 태스크를 실행할 수 있다. 접속된 필터의 집합은,"필터 그래프" 라고 부른다. 예를 들어, 다음 그림은 AVI 파일을 재생하기 위한 필터 그래프를 나타내고 있다.

파일 소스 필터는 하드 디스크로부터 AVI 파일을 읽어낸다. AVI 스플리터 필터는, 파일을 해석해, 압축 비디오 스트림과 오디오 스트림으로 한다. AVI 디컴프레서필터는 비디오 프레임을 디코드한다. 비디오 렌더러 필터는, DirectDraw 또는 GDI 를 사용해, 디스플레이에 프레임을 드로잉(Drawing) 한다. 디폴트 DirectSound 장치 필터는, DirectSound 를 사용해, 오디오 스트림을 재생한다.
애플리케이션으로, 이러한 데이터의 흐름의 모든 것을 관리할 필요는 없다. 애플리케이션 대신에, 필터 그래프 매니저로 불리는 상위 레벨의 구성 요소가 필터를 제어한다. 애플리케이션에서는,"Run" (그래프의 시작으로부터 마지막까지 데이터를 이동한다)나 "Stop" (데이터의 흐름을 정지한다)등의 상위 레벨의 API 호출을 실시한다. 스트림 조작을 보다 세세하게 제어할 필요가 있는 경우는, COM 인터페이스를 통해 필터에 직접 액세스 할 수 있다. 또, 필터 그래프 매니저는 애플리케이션에 이벤트 통지를 건네준다.
필터 그래프 매니저에는 이제 1 개별의 용도가 있다. 필터를 접속해 필터 그래프를 생성하기 위한 메서드를 애플리케이션에 제공하는 것이다. DirectShow 에서는, 이 처리를 간소화하기 위한 다양한 헬퍼-개체도 준비해 있다. 이것들에 대해서는, 문서 중(안)에서 자세하게 설명되고 있다.
DirectShow 애플리케이션의 생성
넓은 의미로, DirectShow 애플리케이션이 실행해야 하는 태스크는 3 개 있다. 이러한 태스크를 다음의 그림에 나타낸다.

처리가 완료 하면, 애플리케이션은 필터 그래프 매니저와 모든 필터를 릴리즈 한다.
DirectShow 는 COM 에 근거하고 있어 필터 그래프 매니저 및 필터는 모두 COM 개체이다. DirectShow 의 프로그래밍을 시작하려면 , COM 클라이언트의 프로그래밍에 관한 일반적인 지식이 필요하다. 이 개요에 대해서는, DirectX SDK 문서의 「COM 의 사용법」을 참조할것. 이외에도, COM 프로그래밍에 대해서는 많은 서적이 있다.
| 2008 디지털제어산업기사 최종발표 (0) | 2008.11.10 |
|---|---|
| 메모리 DC를 이용한 더블 버퍼링 (0) | 2008.10.21 |
| [펀글] MFC tip 10 (0) | 2008.09.24 |
| 채터링을 c로 짤려는데 잘안되네여.. (0) | 2008.09.15 |
| 5장: vector와 vector<bool> (0) | 2008.09.10 |
다이얼로그 베이스에서 보여줘야 할 항목이 많을 때, 약간 지저분해 보이는 경향이 있는데, 단추를 하나 달아서, 안쓰는 항목은 접어 놓고 보면, 상당히 프로그램을 깔끔하게 할 수 있더군요....
그전에 하셔야 할 작업은 다음과 같습니다.
1) 잘 안쓰이는 항목들은 Static Box를 하나 생성해서 모아 놓는다.
2) StaticBox의 이름을 ID_STATIC이 아닌 다른 이름을 붙인다.(여기서는 ID_STATIC_SEP라는 이름을 붙였습니다. )
3) 그 항목을 보여주거나, 안보여주는 기능을 추가하기 위해서 코맨드 버튼이나 메뉴항목을 추가한다.( 여기서는 IDC_BUTTON_TEST라는 이름입니다. )
간단하죠..?? 이렇게 하시고 난 후에 윈도우에 다음과 같은 함수를 추가하시면 됩니다.
코드의 내용은 아까 만든 차일드 윈도우의 영역을 기억해서, 버튼을 한 번 누르면 원래의 윈도우의 모습을, 두번 누르면 차일의 윈도우 영역을 제외한 부분만 보여주는 그런 일을 합니다.
( 아까 만든 버튼의 이벤트 핸들러 입니다. 착오 없으시길... )
void CXXXXDlg::OnExpand()
{
// TODO: Add your control notification handler code here
static BOOL bExpand = TRUE;
Expanding(IDC_STATIC_SEP, bExpand);
bExpand = !bExpand;
}
void CXXXXDlg::Expanding(int nResourceID, BOOL bExpand)
{
static CRect rcLarge;
static CRect rcSmall;
CString strExpand;
if (rcLarge.IsRectNull()){
CRect rcLandMark;
CWnd *pWndLandMark = GetDlgItem(nResourceID);
ASSERT(pWndLandMark);
GetWindowRect(rcLarge);
pWndLandMark -> GetWindowRect(rcLandMark);
rcSmall = rcLarge;
rcSmall.bottom = rcLandMark.top;
}
if (bExpand){
SetWindowPos(NULL, 0 , 0, rcLarge.Width(), rcLarge.Height(),
SWP_NOMOVE | SWP_NOZORDER);
strExpand = " << Test ";
} else {
SetWindowPos(NULL, 0, 0, rcSmall.Width(), rcSmall.Height(),
SWP_NOMOVE | SWP_NOZORDER);
strExpand = " Test >>";
}
SetDlgItemText(IDC_BUTTON_TEST, strExpand);
}
상태바에 그림 출력하시려면Create함수에
CStatusbarCtrl& m_Status = m_wndStatusBar.GetStatusBarCtrl();
m_Status.SetIcon(페인인덱스,
(HICON)LoadImage(AfxGetResourceHandle(),
MAKEINTRESOURCE(그림아디),
32,32,10));
해주시면 됩니다.
더 자세한 정보는 MSDN찾아 보세요..
1.요약
윈도우즈 NT 나 윈도우즈 98 에서 시스템을 강제로 다운시키는 방법에 대해서 알아봅니다.
2.본문
필요한 경우가 거의 없겠지만(바이러스가 아니고서야. ^^;;), 시스템을 강제로 다운시키고자 하는 경우가 있을 수 있습니다. 이런 경우 아래의 예제에서 처럼 어셈블리 코드를 사용하는 방법과 Thread 를 와장창 만들어서 thread 러쉬(?)를 통해서 다운시키는 방법이 있습니다. 아래의 예제를 참고 하세요.
3.예제
if(g_bIsWinNT) {
SetPriorityClass(GetCurrentProcess(),REALTIME_PRIORITY_CLASS);
while(1) {
DWORD dwTid;
HANDLE hThread=CreateThread(NULL,0,LockThread,NULL,0,&dwTid);
SetThreadPriority(hThread,THREAD_PRIORITY_TIME_CRITICAL);
}
} else {
lockpoint:
__asm {
cli
jmp lockpoint
}
}
4.참고
BO2K
* cli : Clear Interrupt Flag
--> 이 어셈블리 코드는 현재 시스템이 다운되는 것을 방지하기 위해서 만들어진
Interrupt Flag 를 제거해버림으로써, 아무도 자신을 건드릴 수 없게 합니다.
(The Intel Architecture Software Developer's Manual)
<Win9x VS Win2000,WinNT 시스템 종료하기>
시스템을 관리하는 프로그램에서 자주 쓰이는 기능인데여...
좀 보기 쉽게 정리된 자료가 없는거 같아서 올려봅니다.....
먼저 Win9x Series...
간단하니까...그냥 함수로 구현한 것만 적어 놓으께여...
void CUpsManagerApp::Win9XSystemReboot()
{
ExitWindowsEx(EWX_REBOOT,0);
}
void CUpsManagerApp::Win9XSystemPowerOff()
{
ExitWindowsEx(EWX_POWEROFF,0);
}
void CUpsManagerApp::Win9XSystemLogOff()
{
ExitWindowsEx(EWX_LOGOFF, 0);
}
먼저 WinNT 및 Win2000 Series...
요건 문제가 쩜 있습니다...
프리빌리지라는 넘을 설정해서 토큰(버스 토큰 아님 --;;;)이라는 넘을 설정줘야 합니다.
뭐하는 넘인지는 MSDN 찾아보면 잘 나오구여... 그냥 시스템 수준의 프로세스 액세스를 할려면... 이거 설정하구 해야한다구 알고 계시면 될겁니다.
글고 이 설정에 관한 방법은 자료실에 이미 계제가 되어 있습니다.
근데.. 또 글을 적어논 이유는 약간의 부연 설명을 달라구여...
지금의 설정대로 하면
ExitWindowsEx(EWX_SHUTDOWN | EWX_REBOOT,0);
ExitWindowsEx(EWX_SHUTDOWN | EWX_POWEROFF,0);
위의 두개의 기능은 당연히 달라야 합니다....
근데... 둘다 리부팅이 됩니다. 원래 하나는 파워 오프되어야 하는데...
아무리 추적해 봐도 왜 그런지 잘 모르겠어여...
전 유피에스 관리 프로그램 지금 짜고 있는데...
바떼리 떨어지면... 시스템을 죽여야 하는데... 이넘이 다시 켜지면 곤란하지여..
그려서... ExitWindowsEx() 함수 대신에 ....
InitiateSystemShutdown() 함수를 써서 구현해봤심더...
엔티4.0하구 윈이천(Professional 버젼)은 잘 동작 하든디...
다른건 아직 테스트 못해봤습니다.
void CUpsManagerApp::WinNTSystemReboot()
{
HANDLE hToken;
TOKEN_PRIVILEGES tp;
LUID luid;
OpenProcessToken(GetCurrentProcess(),
TOKEN_ADJUST_PRIVILEGES | TOKEN_QUERY,
&hToken);
LookupPrivilegeValue(NULL,"SeShutdownPrivilege",&luid);
tp.PrivilegeCount = 1;
tp.Privileges[0].Luid = luid;
tp.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
AdjustTokenPrivileges(hToken, FALSE, &tp, 0, NULL, NULL);
InitiateSystemShutdown(NULL, NULL, 30, FALSE, TRUE);
// ExitWindowsEx(EWX_SHUTDOWN | EWX_REBOOT,0);
}
void CUpsManagerApp::WinNTSystemPowerOff()
{
HANDLE hToken;
TOKEN_PRIVILEGES tp;
LUID luid;
OpenProcessToken(GetCurrentProcess(),
TOKEN_ADJUST_PRIVILEGES | TOKEN_QUERY,
&hToken);
LookupPrivilegeValue(NULL,"SeShutdownPrivilege",&luid);
tp.PrivilegeCount = 1;
tp.Privileges[0].Luid = luid;
tp.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
AdjustTokenPrivileges(hToken, FALSE, &tp, 0, NULL, NULL);
InitiateSystemShutdown(NULL, NULL, 30, FALSE, FALSE);
// ExitWindowsEx(EWX_SHUTDOWN | EWX_POWEROFF,0);
}
void CUpsManagerApp::WinNTSystemLogOff()
{
ExitWindowsEx(EWX_LOGOFF, 0);
}
1.요약
소수점이 있는 나눗셈 연산을 정수로 계산하여 계산 속도가 빠르고 정확한 숫자를 얻을 수 있는 방법에 대해서 알아보겠습니다.
2.본문
정수로 계산은 소수점 계산보다 연산 속도가 빠릅니다. 그리고 정확한 숫자값을 얻기 위해서는 나누기 전에 왼쪽으로 16-bit shift하고, 동등한 16-bit의 2진 숫자를 주어야 합니다. 이것은 나누기 전에 100,000으로 곱셈을 한 효과가 있습니다. 이렇게 함으로써 소수점을 계산하지 않아도 됩니다.
3.예제
1) 10 / 85 = x;
10을 100,000으로 곱하면, 1,000,000이 나온다.
1,000,000 / 85 = 11764를 먼저 계산하고,
결과값 11764를 100,000으로 나누면 0.11764가 나온다.
2)
int ratio = ((( dege - px2) < < 16) / (px1 - px2));
px1 = edge;
py1 = py2 + (((py1 - py2) * ratio) >> 16));
3)
float ratio = (float)((edge - px2) / (px1 - px2));
px1 = edge;
py = py2 + (int)(((float)(py1 - py2) * ratio));
[결과]
2)연산속도가 3)연산속도보다 약 2배정도 빠른결과가 나옵니다.
4.참고
Real-Time Strategy Game Programming using Ms DirectX p.318
[요약]
Explorer 에서 파일 아이콘을 더블클릭할 경우 파일의 확장명에 따라 연결되어 있는 프로그램이 동작하게 되어 있다. 하지만 연결되어 있는 프로그램이 없을 경우 "연결 프로그램 찾기" 다이얼로그가 화면에 나타난다.
[추가 정보]
파일 아이콘에 연결된 프로그램이 없을 경우 연결 프로그램을 지정하도록 "연결 프로그램 찾기" 다이얼로그를 프로그램적으로 띄우는 방법은 ShellExecuteEx API 를 Call 할 때 "Openas" 를 파라미터로 사용하면 된다.
우선 ShellExecuteEx를 Call하기 전에 FindExecutable API를 사용하여 파일의 프로그램 연결여부를 우선 알아보도록 한다. 만약 연결된 응용프로그램이 있을 경우 SHELLEXECUTEINFO structure에 "Open" 파라미터를 사용하고, 그렇지 않을 경우 "Openas"를 사용하면 된다. 이 파라미터에 의해 ShellExecuteEx 가 "연결 프로그램 찾기" 다이얼로그를 화면에 나타내게 된다.
다음은 위 내용에 대한 Sample code이다.
// Get the name of the file to be openend.
CFileDialog dlg(TRUE);
if (dlg.DoModal() == IDOK ) {
CString strFile = dlg.GetPathName();
// See if there is an association for this file.
char strExecutable[FILENAME_MAX];
int result = (int)FindExecutable((LPCTSTR)strFile, NULL,
(LPTSTR)&strExecutable);
if (result == 31) { // No Associated .EXE file
AfxMessageBox("There is no association for the specified file type.
The 'Open With...' dialog box will now be displayed.");
SHELLEXECUTEINFO sei = {sizeof(sei), 0, m_hWnd, "Openas",
(LPCSTR)strFile, NULL, NULL, SW_SHOWNORMAL,
AfxGetApp()->m_hInstance};
// Invoke the "Open With..." dialog box before opening the selected file.
ShellExecuteEx(&sei);
} else if (result >= 32 ) { // Found an Associated .EXE file
AfxMessageBox("The file will now be opened with the associated program...");
SHELLEXECUTEINFO sei = {sizeof(sei), 0, m_hWnd, "Open",
(LPCSTR)strFile, NULL, NULL, SW_SHOWNORMAL,
AfxGetApp()->m_hInstance};
// Open the selected file.
ShellExecuteEx(&sei);
} else { // Error condition.
AfxMessageBox("Some other problem has caused 'FindExecutable' to fail.");
}
}
보통 윈도우 Application은 화려한 GUI를 자랑하며 Application이 만들어 집니다.
그러나 서버에서 실행되는 프로그램인 경우하나의 콘솔 화면에서 여러 GUI를 띄어 작업을 하게 되지요.
보통은 하나의 Application에 하나의 콘솔에 여러개의 윈도우를 생성해 프로그램 됩니다. 물론 콘솔도 하나의 윈도우지만요.
그럼 여기서 간단히 윈도우 Application에서 콘솔을 띄어 Text Edit에 있는 문자를 콘솔에 찍는 API 함수를 소개합니다.
비교적 간단하고 여러군데서 사용가능하니 많은 참조 바랍니다.
1. 윈도우에서 콘솔 띄우기
BOOL AllocConsole()
2. 생성된 콘솔에 문자열 보내기
CString str;
str = "문자열"
DWORD dwWrite;
HANDLE hOut = GetStdHandle(STD_OUTPUT_HANDLE);
WriteFile(hOut, str, str.GetLength(), &dwWrite, NULL);
3. 생성된 콘솔없애기
BOOL FreeConsole()
함수의 자세한 사용은 MSDN에서 참고하세요.
<제어판에서 큰글꼴로 설정했을경우에도 일정한 크기의 글꼴 지정>
CDC* pDC = GetDC();
int nSize1 = 100; // 작은 글꼴에서 보여지는 글꼴 크기
int nSize2 = MulDiv(nSize1, 96, pDC->GetDeviceCaps(LOGPIXELSY));
// nSize1의 크기를 현재 디스플레이의 인치당 픽셀수로재계산한다.
m_Font.CreatePointFont(nSize2, "굴림체", pDC);
// 단순히 폰트명과 폰트크기로 생성할때
m_Button.SetFont(&m_Font);
이렇게 해서 앞에 올린 코드를 대신하면 제어판에서 설정한 큰글꼴, 작은글꼴의 값에 상관없이 일관된 크기의 폰트를 지정할 수 있습니다. 큰글꼴로 설정하면 글자가 잘리는 현상을 막을 수 있죠.
256 칼라의 비트맵을 화면에 뿌려줍니다. 물론 투명색을 지정하는 방식이구요.
그럼 소스 나갑니다.
int CCISBitmap::Width()
{
BITMAP bm;
GetBitmap(&bm);
return bm.bmWidth;
}
int CCISBitmap::Height()
{
BITMAP bm;
GetBitmap(&bm);
return bm.bmHeight;
}
void CCISBitmap::DrawTransparent(HDC hDC, int x, int y, COLORREF crColour)
{
COLORREF crOldBack = SetBkColor(hDC,m_crWhite);
COLORREF crOldText = SetTextColor(hDC,m_crBlack);
CDC dcImage, dcTrans;
// Create two memory dcs for the image and the mask
dcImage.m_hDC = CreateCompatibleDC(hDC);
dcTrans.m_hDC = CreateCompatibleDC(hDC);
// Select the image into the appropriate dc
CBitmap* pOldBitmapImage = dcImage.SelectObject(this);
// Create the mask bitmap
CBitmap bitmapTrans;
int nWidth = Width();
int nHeight = Height();
bitmapTrans.CreateBitmap(nWidth, nHeight, 1, 1, NULL);
// Select the mask bitmap into the appropriate dc
CBitmap* pOldBitmapTrans = dcTrans.SelectObject(&bitmapTrans);
// Build mask based on transparent colour
dcImage.SetBkColor(crColour);
dcTrans.BitBlt(0, 0, nWidth, nHeight, &dcImage, 0, 0, SRCCOPY);
// Do the work - True Mask method - cool if not actual display
BitBlt(hDC, x, y, nWidth, nHeight, dcImage.m_hDC , 0, 0, SRCINVERT);
BitBlt(hDC, x, y, nWidth, nHeight, dcTrans.m_hDC , 0, 0, SRCAND);
BitBlt(hDC, x, y, nWidth, nHeight, dcImage.m_hDC , 0, 0, SRCINVERT);
// Restore settings
dcImage.SelectObject(pOldBitmapImage);
dcTrans.SelectObject(pOldBitmapTrans);
pOldBitmapImage->DeleteObject();
pOldBitmapTrans->DeleteObject();
SetBkColor(hDC,crOldBack);
SetTextColor(hDC,crOldText);
}
입니다.
음.. 그런데 이게 좀 느려요. --;.
투명색 없이 출력하는 루틴은 아래껍니다.
void CCISBitmap::DrawBitmap(HDC hDC, int x, int y)
{
CDC MemDC;
MemDC.m_hDC = CreateCompatibleDC (hDC);
int nWidth = Width();
int nHeight = Height();
CBitmap *pBitmap = (CBitmap *)MemDC.SelectObject (this);
BitBlt (hDC,x,y,nWidth,nHeight,MemDC.m_hDC,0,0,SRCCOPY);
MemDC.SelectObject (pBitmap);
pBitmap->DeleteObject();
pBitmap = NULL;
}
그리고 헤더는 이렇게 해주세요.
public:
void DrawBitmap(HDC hDC, int x, int y);
CCISBitmap();
virtual ~CCISBitmap();
// Functions
int Height();
int Width();
virtual void DrawTransparent(HDC hDC, int x, int y, COLORREF crColour);
private:
COLORREF m_crBlack;
COLORREF m_crWhite;
그리고요.. 또.. 생성자에 COLORREF 를 초기화 해주심 되구요
이건 CBitmap 을 상속받았습니다.
IE가 죽을 때 트레이의 아이콘이 모두 사라지는 경우가 있습니다.
특히 트레이에 숨어버리는 프로그램이 그렇게 되면 참으로 난감해지죠.
IE 4이상에서는 그런 일을 막기 위해서 죽은 후 태스크바가 만들어질 때 모든 top-level 윈도우에 메시지를 보내줍니다. 그 메시지를 받으면 트레이에 새로 아이콘을 넣어주면 됩니다.
MSDN에 있는 내용이지만 모르시는 분들이 많더군요.
소스를 보면 다음과 같습니다.
LRESULT CALLBACK WndProc(HWND hWnd, UINT uMessage, WPARAM wParam, LPARAM lParam)
{
static UINT s_uTaskbarRestart;
switch(uMessage){
case WM_CREATE:
s_uTaskbarRestart = RegisterWindowMessage(TEXT("TaskbarCreated"));
break;
default:
if(uMessage == s_uTaskbarRestart)
AddTaskbarIcons();
break;
}
return DefWindowProc(hWnd, uMessage, wParam, lParam);
}
RegisterWindowMessage(TEXT("TaskbarCreated")); 는 TaskbarCreated라는 이름의 메시지를 시스템에 대해서 유일하게 만들어주는 함수입니다. 이미 이 이름으로 메시지가 등록되어 있을 경우에는 그 값을 돌려줍니다.
따라서 프로그램이 시작할 때 한번 실행해서 그 값을 저장해줘야 합니다.
그리고 해당 메시지가 오면 그 때 트레이에 아이콘을 새로 넣으면 되겠죠.
MFC의 경우는 메시지의 값이 상수로 정해져 있지 않기 때문에 메시지 맵에 붙이는 건 안될 것 같습니다. CWnd::WindowProc이나 PretranslateMessage에서 메시지 값을 확인해서 처리해주면 되겠죠.
- MFC의 경우
윈도우는 tray icon에 있는 아이콘들을 보여줄때."TaskbarCreated" 라는 윈도우 메세지를 보여줍니다...
따라서 우리는 이 윈도우 메세지를 등록해서 사용하면 됩니다.
UINT g_uShellRestart;
g_uShellRestart = RegisterWindowMessage(__Text("TaskbarCreated"));
이렇게 해서..
Message Map 에서..
ON_REGISTERED_MESSAGE(g_uShellRestart, OnTrayShow)
이런식으로 메세지 핸들러를 설치하시고..
LRESULT CMyDlg::OnTrayShow(WPARAM wParam, LPARAM lParam)
{
m_Tray.ShowTray(); // TrayIcon을 다시 보여줍니다. ShowTray 는 임시.
}
이런식으로 해주시면 됩니다..
테스트를 해보시고 싶으시다면..Ctrl+Alt+Del 을 눌러서..Explorer 를 죽이세요..
그러면 tray icon들이 사라질텐데..
이 메세지를 등록한 프로그램들은 ..여전히 남아있는 모습을 볼 수 있습니다.
일단 다이알로그 박스의 핸들을 얻어야겠지요?
HWND hWnd;
hWnd = ::FindWindow("클래스 명", "타이틀 명");
보통 다이알로그박스는 클래스명이 "#32770" 이죠,
따라서 ::FindWindow("#32770", NULL); 이렇게하면 타이틀에 관계없이 첫번째 다이알로그 박스를 찾아 핸들을 넘겨주죠 그담엔 아래와 같이 해보길...
::PostMessage(hWnd, WM_COMMAND, IDOK, 0L); //"OK" 버튼 누름
::PostMessage(hWnd, WM_COMMAND, IDNO, 0L); //"NO" 버튼 누름
::PostMessage(hWnd, WM_COMMAND, IDCANCEL, 0L); //"CANCEL" 버튼 누름
해당 헤더파일 : imm.h 해당 라이브러리 파일 : imm32.lib
한글모드와 영문모드를 전환하는 함수는 다음 두가지입니다.
1. 한글모드로 전환하는 방법
void CHanengClass::SetHanMode(HWND hWnd)
{
HIMC hIMC = ImmGetContext(hWnd);
DWORD dwConv, dwSent;
DWORD dwTemp;
ImmGetConversionStatus(hIMC,&dwConv,&dwSent);
dwTemp = dwConv & ~IME_CMODE_LANGUAGE;
dwTemp |= IME_CMODE_NATIVE;
dwConv = dwTemp;
ImmSetConversionStatus(hIMC,dwConv,dwSent);
ImmReleaseContext(hWnd,hIMC);
}
2. 영문모드로 전환하는 방법
void CHanengClass::SetEngMode(HWND hWnd)
{
HIMC hIMC = ImmGetContext(hWnd);
DWORD dwConv, dwSent;
DWORD dwTemp;
ImmGetConversionStatus(hIMC,&dwConv,&dwSent);
dwTemp = dwConv & ~IME_CMODE_LANGUAGE;
dwTemp |= IME_CMODE_ALPHANUMERIC;
dwConv = dwTemp;
ImmSetConversionStatus(hIMC,dwConv,dwSent);
ImmReleaseContext(hWnd,hIMC);
}
<Dialog의 Min/Max/Close Box를 Run Time Show/Hide>
// 아래의 세 메세지 핸들러는
// Dialog Client Area에 만든 각 Button을 위한것입니다.
// 이 각 Button들을 클릭하면 Title Bar상의 해당 Box가 Show/Hide되죠.
void CTestDlg::OnBtnMin()
{
// TODO: Add your control notification handler code here
static BOOL bEnable = TRUE;
bEnable = bEnable ? FALSE : TRUE;
if(bEnable)
ModifyStyle(0,WS_MINIMIZEBOX);
else
ModifyStyle(WS_MINIMIZEBOX,0);
PostMessage(WM_NCACTIVATE,TRUE);
}
void CTestDlg::OnBtnMax()
{
// TODO: Add your control notification handler code here
static BOOL bEnable = TRUE;
bEnable = bEnable ? FALSE : TRUE;
if(bEnable)
ModifyStyle(0,WS_MAXIMIZEBOX );
else
ModifyStyle(WS_MAXIMIZEBOX ,0);
PostMessage(WM_NCACTIVATE,TRUE);
}
void CTestDlg::OnBtnClose()
{
// TODO: Add your control notification handler code here
static BOOL bEnable = TRUE;
CMenu* pSysMenu = GetSystemMenu(FALSE);
if (pSysMenu != NULL) {
bEnable = bEnable ? FALSE : TRUE;
if(bEnable)
pSysMenu->EnableMenuItem(SC_CLOSE, MF_ENABLED | MF_BYCOMMAND);
else
pSysMenu->EnableMenuItem(SC_CLOSE, MF_DISABLED | MF_BYCOMMAND);
}
}
<error LNK2001: unresolved external symbol _main>
error LNK2001: unresolved external symbol _main
이 에러가 발생하는 경우는 크게 두가지가 있습니다.
1. API로 프로그래밍을 처음 하시는 분들이 흔히 하는 실수 같습니다.
윈도우에서 프로그램은 크게 두가지로 분류할 수 있습니다.
도스처럼 console 창에 텍스트만을 출력하는 console 프로그램과 흔히 쓰는 GUI를 가진 프로그램이 있죠.
Visual C++에서 프로젝트를 만들 때
Win32 Application : WinMain 함수에서 시작하게 되는 GUI 프로그램
Win32 Console Application : main 함수에서 시작하는 console 프로그램
이 두가지가 있습니다.
제목에 적은 것 같은 에러가 나는 분들은 대부분 GUI 프로그램을 만드시려고 하고 WinMain은 만드셨는데, 프로젝트를 만들 때 console application을 선택하신겁니다. 반대로 WinMain이 없다고 에러가 나오면 GUI 프로젝트를 선택하고서 main 함수를 작성하신 것이겠죠.
자, 그럼 어떻게 해결하느냐. 설정을 바꿔주면 됩니다. 프로젝트 세팅(Alt + F7)에서 Link탭을 누르면 제일 아래에 에디트 박스가 보이죠? 잘 보면 /subsystem:console 이라고 써있을 겁니다. 이걸 /subsystem:windows로 바꿔주세요. (또는 상황에 따라서 그 반대로 해줄 수도 있겠죠) 이 옵션의 역할은 링커에게 있어서 이 프로그램이 어떤 함수로부터 시작해야 하는지를 알려주는 겁니다. 이 옵션이 console이라면 main을, windows라면 WinMain을 찾아서 그 함수에서부터 프로그램이 시작하게 하는거죠.
2. ATL에서 컨트롤을 만들 때 이 에러가 날 수 있습니다.
디버그에서는 잘 컴파일이 되던게 릴리즈로 빌드하면 저 에러가 날 수 있습니다. ATL에서는 생성되는 코드의 크기를 최소화 하기 위해서 CRT (C RunTime) 함수의 일부를 제한하고 있기 때문이죠(정확히 말하자면 start up 코드를 넣지 않습니다). 그런데 프로젝트에서 특정 C 함수를 사용하면 ATL에서 제한한 CRT의 기능이 필요해지고 따라서 에러가 나는겁니다.
이 해결책도 간단합니다.
a. 프로젝트 세팅에서 predefined keyword를 찾아서 _ATL_MIN_CRT를 지워주세요.
b. 초기화가 필요한 CRT 함수를 사용하지 마세요. -_-; MSDN에 따르면 strcmp대신 lstrcmp를 사용하는 식으로 피해갈 수 있다고 합니다.
자세한건 MSDN에서 _ATL_MIN_CRT를 찾아보세요. (색인에서 입력하면 나옵니다.)
1.요약
특정 Thread 나 Window 에 아무런 영향을 끼치지 않으면서 단순히 그 Thread 나 Window 가 살아있는지를 확인하고 싶을때 '친절한 메세지' 를 사용하시면 됩니다.
2.본문
MSDN 의 '색인' 에는 나와있지 않지만(MSDN 에서 특이하다 싶은것들은 일반적으로 '색인'에 없죠. ^^), 윈도우 메세지 종류에 WM_NULL 이라는 메세지가 존재합니다. MSDN 이나 다른 책에서 WM_NULL 메세지를 benign message 라고 소개하고 있습니다.
WinUser.H 파일에 아래와 같이 정의되어 있습니다.
#define WM_NULL 0x0000
이 메세지는 메세지 큐에 날라가긴 하지만, 어느 윈도우에서도 이 메세지를 처리하지 않기 때문에 그냥 메세지 큐에 들어가기만 하는 메세지입니다. 그럼 윈도우는 왜 이런 메세지를 만들어 놓은 걸까요? Debugging Application 에서 보면 이 메세지를 정지해있는 혹은 메세지큐가 idle 상태에 있는 thread 를 깨우기 위해서 ( 마치 술 먹기 전에 밥먹는 것처럼..) 사용하고 있습니다. 또한 해당 윈도우가 정상적으로 메세지를 받을 수 있는 상태인지 단순히 확인만 하고 싶을때 ( 이런 경우가 종종있는데, 어떤 메세지를 보내야 할지 난감할때가 있습니다.
3.예제
// 일반 메세지 보내는것과 같습니다.
PostMessage(m_hwndTarget, WM_NULL, 0,0);
- the end of this article -
| 메모리 DC를 이용한 더블 버퍼링 (0) | 2008.10.21 |
|---|---|
| directshow(다이렉트쇼)프로그래밍 (0) | 2008.10.19 |
| 채터링을 c로 짤려는데 잘안되네여.. (0) | 2008.09.15 |
| 5장: vector와 vector<bool> (0) | 2008.09.10 |
| [STL] DEQUE (0) | 2008.09.10 |
re: 소프트웨어 적인 채터링방법좀.. |
|---|
출처 : 직접
| directshow(다이렉트쇼)프로그래밍 (0) | 2008.10.19 |
|---|---|
| [펀글] MFC tip 10 (0) | 2008.09.24 |
| 5장: vector와 vector<bool> (0) | 2008.09.10 |
| [STL] DEQUE (0) | 2008.09.10 |
| XML Programming with C++ (1) | 2008.08.31 |
vector 컨테이너 클래스는 기존 C 배열의 개념을 일반화시킨 것이다. 배열과 마찬가지로, vector도 첨자로 접근이 가능하며, 이 때 첨자의 범위는 0부터 (원소의 갯수 - 1)까지이다. 또한 [] 연산자를 이용해서 vector에 값을 대입하거나 vector로부터 값을 추출할 수 있다. 그러나, 이러한 공통점외에 배열과 vector는 다음과 같은 차이점을 가지고 있다.
표준 라이브러리의 vector 컨테이너 클래스는 7장에서 다룰 deque('덱'이라고 발음한다.)과 여러모로 비교가 된다. vector와 같이 deque도 인덱싱이 가능한 자료구조이다. 이 둘의 가장 큰 차이점은 deque은 컨테이너의 앞과 끝에서의 삽입이 효율적인 반면에, vector는 끝에서 삽입할 때만 효율적이라는 것이다. 대개는 둘중 어느 것을 사용해도 상관없지만, 일반적으로 vector를 사용하는 것이 좀더 작은 실행화일을 만들 수 있는 반면에, deque은 수행되는 연산의 종류에 따라 조금 빠른 프로그램을 만들기도 한다.
vector를 사용하려면 vector 헤더화일을 포함시켜야 한다.
#include <vector>
이 절에서는 vector가 제공하는 멤버 함수들에 관해 좀 더 자세히 살펴본다. 앞으로도 계속 언급하겠지만, 멤버함수는 기초적인 연산들을 제공하는 반면에, 13장과 14장에서 소개할 generic 알고리듬을 사용함으로써 표준 라이브러리가 제공하는 자료구조들을 보다 유용하게 사용할 수 있게 된다.
vector는 템플릿 클래스이므로 vector에 담을 원소의 타입을 명시해 주어야 한다. 원소의 타입은 integer나 double과 같은 primitive 타입이나, 포인터 타입이 될 수도 있고, 사용자 정의 타입이 될 수도 있다. 사용자 정의 타입의 경우에는 기본 생성자가 반드시 정의되어 있어야 한다. 복사 생성자도 명시적으로든 묵시적으로든 반드시 존재해야 한다.
|
배열과 마찬가지로, vector도 자신이 담게 될 원소의 갯수를 정수 인자로 하여 선언하는 것이 가장 흔한 경우다.
vector<int> vec_one(10);
(이와 같은 상황에서 vector를 생성하기 위해 사용되는 생성자는 키워드 explicit로 선언된다. 이렇게 함으로써 이 생성자가 변환 연산자로 사용되는 것을 막을 수 있다. 이렇게 하지 않으면, 본의아니게 정수를 vector로 변환하는 경우가 발생할 수 있기 때문이다.)
vector를 생성하기 위해서 사용할 수 있는 생성자에는 여러가지가 있다. vector의 사이즈 뿐만 아니라, vector의 원소들을 초기화하는데 사용되는 상수값을 제공하는 생성자도 있다. 사이즈가 명시되지 않으면, vector는 아무런 원소를 포함하지 않은 상태로 생성되게 되며, 원소가 추가될 때 자동적으로 사이즈가 증가하게 된다. 복사 생성자는 다른 vector로부터 클론을 생성할 수 있다.
vector<int> vec_two(5, 3); // 복사 생성자 vector<int> vec_three; // 가장 일반적인 형태 vector<int> vec_four(vec_two); // 대입에 의한 초기화
시작 반복자와 끝 반복자 pair를 사용하여 다른 콜렉션의 원소들로 vector를 초기화할 수 있다. 이들 인자로 들어가는 반복자의 형태는 아무것이나 가능하며, 반복자를 제공하는 컨테이너에 담긴 값들이기만 하면 이들 값들을 가지고 초기화가 가능하다.
vector<int> vec_five(aList.begin(), aList.end());
| ▶ 생성자와 반복자 |
| Because it requires the ability to define a method with a template argument different from the class template, some compilers may not yet support the initialization of containers using iterators. In the mean time, while compiler technology catches up with the standard library definition, the Rogue Wave version of the standard library will support conventional pointers and vector iterators in this manner. |
vector간의 대입도 가능하며, 이때 대입 연산자의 좌변은 우변 vector의 복사본을 가지게 된다.
vec_three = vec_five;
assign() 멤버함수는 대입 연산자와 비슷하지만, 더 기능이 많다. 인자가 더 많을 경우도 있다. 대입과 마찬가지로, 컨테이너에 담긴 값들은 인자로 명시된 값들로 바뀌게 된다. 두가지 형태의 assign()이 있는데, 첫번째는 다른 컨테이너의 서브 시퀀스를 가리키는 두개의 반복자를 취한다. 이 서브 시퀀스로부터의 값들은 받는 쪽에서의 새로운 값들이 된다. assign()의 두번째 형태는 갯수와 컨테이너 원소 타입의 값이(이것은 생략 가능) 인자로 제공된다. 함수호출을 한뒤에는 count로 명시된 갯수의 원소들만 가지게 되고, 이 원소들은 기본값과 같거나, 명시한 초기값과 같게 된다.
vec_six.assign(list_ten.begin(), list_ten.end()); vec_four.assign(3, 7); // '7'을 3개 대입 vec_five.assign(12); // '0'을 12개 대입
원소의 타입이 소멸자를 정의하고 있다면, 콜렉션으로부터 이들 원소가 삭제될 때, 이 소멸자를 호출하게 된다.
마지막으로, swap() 연산자를 통해 두 vector간에 각자 가지고 있던 원소들을 모조리 바꿔치기 할 수도 있다. 인자로 들어가는 컨테이너는 수신자의 값들을 가지게 되고, 수신자는 인자로 들어가는 컨테이너의 값들을 가지게 된다. 이 swap()은 매우 효율적이기 때문에, 원소별로 전송할 때는 반드시 이것을 사용해야 한다.
vec_three.swap(vec_four);
vector 클래스는 많은 수의 타입 정의를 포함하고 있다. 이들은 선언문에서 가장 많이 사용된다. 예를 들어, 정수 vector의 반복자는 다음과 같이 선언할 수 있다.
vector<int>::iterator location;
iterator 뿐만 아니라 다음과 같은 타입들도 정의되어 있다.
| value_type | 벡터가 관리하는 원소들의 타입 |
| const_iterator | 하부 시퀀스를 변경할 수 없는 반복자 |
| reverse_iterator | 역 이동 반복자 |
| const_reverse_iterator | 위 두가지 성질을 동시에 가지는 반복자 |
| reference | 벡터 원소에 대한 참조 |
| const_reference | 원소를 변경할 수 없는 참조 |
| size_type | 컨테이너의 사이즈를 참조할 때 사용되는 비부호 정수형 |
| difference_type | 반복자간의 거리차를 나타낼 때 사용되는 부호 정수형 |
| allocator_type | 벡터의 메모리를 관리하는데 사용되는 할당기 타입 |
특정 인덱스 위치에서 vector가 관리하는 값을 접근하거나 변경할 때는 첨자 연산자를 사용하며, 이는 일반 배열과 동일하다. 또한, 인덱스 값의 유효성에 대한 검사를 하지 않는다. 상수 vector를 인덱싱하면 상수 레퍼런스가 생성된다. 유요한 인덱스 범위를 벗어나는 vector를 인덱싱할 때는 어떤 결과가 나올지 예측할 수 있다.
cout << vec_five[1] << endl; vec_five[1] = 17;
첨자 연산자를 대신해서, 멤버함수 at()을 사용할 수 있다. 이 함수는 첨자 연산자와 동일한 인자를 가지고 동일한 값을 반환한다.
front() 멤버 함수는 vector의 맨 앞에 있는 원소를 반환하고, back()은 맨 마지막 원소를 반환한다. 이 두 함수 모두 상수 vector에 적용하면, 상수 레퍼런스를 반환한다.
cout << vec_five.front() << " ... " << vec_five.back() << endl;
일반적으로 vector에는 세가지의 서로 다른 '사이즈'가 존재한다. 첫째로, 현재 vector가 가지고 있는 원소의 갯수이다. 둘째로 새로운 메모리 할당없이 vector가 확장될 수 있는 최대 사이즈이다. 세째는 vector가 가질 수 있는 사이즈의 상한선이다. 이들 세값들은 각각 size(), capacity(), max_size() 멤버함수에 의해 얻을 수 있다.
cout << "size: " << vec_five.size() << endl; cout << "capacity: " << vec_five.capacity() << endl; cout << "max_size: " << vec_five.max_size() << endl;
max_size()는 사용가능한 메모리의 양 또는 size_type 자료형이 나타낼 수 있는 최대값에 의해 제한된다. 현재 사이즈와 capacity를 규명하기가 더 어렵다. 다음 절에서 살펴보겠지만, 다양한 방법으로 vector로부터 원소들을 추가하거나 삭제할 수 있다. vector로부터 원소들을 제거할 때, vector에 대한 메모리는 반환되지 않으며, 따라서, size는 줄어도 capacity는 그대로이다. 기존에 확보된 capacity를 넘지 않으면, 삽입으로 인해 새로 메모리를 할당하지는 않는다.  Memory Management
Memory Management
삽입으로 인해 capacity가 넘치게 되면, vector 원소들을 담을 새로운 블럭을 할당하게 된다. 그리고 나서, 원소 타입에 대한 대입 연산자를 사용하여 값들을 새로 할당된 메모리로 복사하고, 예전 메모리는 삭제한다. 이는 상당히 비싼 연산이므로, vector 데이터 타입은 프로그래머에게 vector의 capacity를 정할수 있는 방법을 제공한다. reserve() 멤버 함수는 vector가 적어도 주어진 사이즈까지는 자라날 것이라는 것을 나타내는 vector에 대한 지시자이다. reserve() 인자로 주어진 값이 현재 capacity보다 크면, 메모리 반환이 일어나고, 인자로 주어진 값이 새로운 capacity가 된다. (??) capacity가 이미 인자값을 초과하고 있다면, 메모리 반환은 일어나지 않는다. reserve()를 호출해도 vector의 사이즈와 원소값들은 바뀌지 않는다.(단, 메모리 반환이 일어나면 원소값들을 이동하는 경우는 제외한다.)
vec_five.reserve(20);
메모리 반환이 일어나면, vector들의 원소를 참조하는 모든 레퍼런스, 포인터, 반복자들은 모두 무효가 된다.
empty() 멤버 함수는 현재 vector의 사이즈가 0일 때 참이 된다. (vector의 capacity와는 무관하다.) 이함수를 사용하는 것이 size()의 리턴값과 0을 비교하는 것보다 훨씬 효과적이다.
cout << "empty is " << vec_five.empty() << endl;
resize() 멤버 함수는 vector의 사이즈를 인자값으로 만들어버린다. 이때 필요하다면 vector의 끝부분의 원소값들이 삭제되거나 첨가된다. 옵션인 두번째 인자는 새로운 원소가 추가될 때의 초기값들로 사용된다. 만약 원소 타입에 대한 소멸자가 정의되어 있다면, 콜렉션으로부터 제거되는 원소값들에 대해 소멸자가 호출된다.
// become size 12, adding values of 17 if necessary vec_five.resize (12, 17);
앞에서 언급했던 바와 같이, vector 클래스는 사이즈가 증가하거나 감소할 수 있다는 점에서 일반 배열과 다르다. 삽입으로 인해 vector의 원소의 수가 현재 원소값들을 담는데 사용되는 메모리 블럭의 capacity를 초과하게 되면, 새로운 메모리 블럭이 할당되어 이곳으로 원소값들을 복사한다. Costly Insertions
push_back()을 사용하면 vector의 끝에 새 원소를 첨가할 수 있다. 현재 할당된 메모리에 공간이 남아 있다면, 이 연산은 매우 효율적이다(상수시간).
vec_five.push_back(21); // add element 21 to end of collection
이에 대응되는 삭제 연산으로 pop_back()이 있다. 이 연산은 vector의 사이즈를 줄이고, capacity에는 변화를 주지 않는다. 컨테이너 타입이 소멸자를 정의하고 있다면, 삭제되는 원소에 대해 소멸자를 호출하게 된다. pop_back() 연산도 매우 효율적이다. (deque 클래스는 콜렉션의 앞과 뒤에서 삽입과 삭제를 허용한다.) 이들 함수들은 deque를 자세히 설명하고 있는 7장에서 설명한다.
insert() 멤버 함수를 사용하면 좀더 일반적인 삽입 연산을 행할 수 있다. 삽입할 위치는 반복자로 지정하고, 삽입은 명시된 위치의 바로 앞에서 일어난다. 정해진 갯수의 상수 원소들은 단 한번의 함수 호출로 삽입될 수 있다. 한번의 호출로 한블럭의 원소들을 삽입하는 것은 하나씩 삽입하는 것보다 훨씬 효율적이다. 한번의 호출로 기껏해야 한번의 할당만 수행하면 되기 때문이다.
// find the location of the 7 vector<int>::iterator where = find(vec_five.begin(), vec_five.end(), 7); vec_five.insert(where, 12); // then insert the 12 before the 7 vec_five.insert(where, 6, 14); // insert six copies of 14
vec_five.insert(where, vec_three.begin(), vec_three.end());
vector의 마지막 원소를 삭제하는 pop_back() 멤버 함수뿐만 아니라, 위치를 지정하는 반복자를 이용하여 vector의 중간에서 원소들을 삭제하는 함수들도 있다. erase()가 바로 그 함수이다. 두가지 형태가 있는데, 첫째는 한개의 반복자를 인자로 받아 한개의 원소값을 제거하고, 둘째는 한쌍의 반복자를 인자로 받아 이 반복자가 가리키는 범위내의 모든 값들을 삭제한다. vector의 사이즈는 줄어들고, capacity는 줄어들지 않는다. 컨테이너 타입이 소멸자를 정의하고 있다면, 삭제되는 값에 대해 소멸자를 호출한다.
vec_five.erase(where); // erase from the 12 to the end where = find(vec_five.begin(), vec_five.end(), 12); vec_five.erase(where, vec_five.end());
begin()과 end() 멤버 함수는 컨테이너에 대한 임의접근 반복자를 리턴한다. 이들 연산들이 반환하는 반복자들도 원소를 삽입하거나 삭제한 뒤에 무효가 될 수 있다. rbegin()과 rend() 멤버 함수는 앞과 비슷한 반복자를 반환하지만, 이들 반복자는 반대방향으로 원소들을 접근한다. 만약 컨테이너가 상수로 선언되어 있다거나, 대입 연산자의 대상이나 인자가 상수라면, 이들 연산들은 상수 반복자들을 반환할 것이다.
vector는 자신이 특정값을 포함하고 있는지를 결정하는데 사용되는 연산을 직접 제공하지 않는다. 그러나, find()나 count()(13.3.1절과 13.6.1절) generic 알고리듬들이 이러한 목적으로 사용될 수 있다. 예를 들어, 다음 명령문들은 정수 vector가 17이라는 수를 포함하고 있는지를 검사하고 있다.
int num = 0;count (vec_five.begin(), vec_five.end(), 17, num);if (num) cout << "contains a 17" << endl;else cout << "does not contain a 17" << endl;
vector는 자신이 관리하는 원소들을 자동으로 순서를 유지시키지 않는다. 그러나, sort() generic algorithm을 사용하여 vector내의 원소들을 순서대로 나열할 수 있다. 가장 간단한 형태의 정렬은 비교할 때 원소타입에 대해 less-than 연산자를 사용한다. 또다른 generic 알고리듬은 프로그래머가 명시적으로 비교 연산자를 지정할 수 있도록 하고 있다. 에를 들어, 다음은 오름차순이 아닌 내림차순으로 원소들을 배치하고 있다.
// sort ascendingsort(aVec.begin(), aVec.end());// sort descending, specifying the ordering function explicitlysort(aVec.begin(), aVec.end(), greater<int>() );// alternate way to sort descendingsort(aVec.rbegin(), aVec.rend());
14장에서 설명하고 있는 많은 연산들이 ordered 콜렉션을 담고 있는 vector들에 적용될 수 있다. 예를 들어, 두개의 vector가 merge() generic 알고리듬을 사용하여 합쳐질 수 있다. (14.6절)
// merge two vectors, printing outputmerge(vecOne.begin(), vecOne.end(), vecTwo.begin(), vecTwo.end(), ostream_iterator<int,char>(cout, " "));
vector를 정렬할 때는 find()와 같이 선형 순회 알고리듬 대신에 보다 효과적인 이진 검색 알고리듬을 사용한다.(?)
13장에서 설명하는 대부분의 알고리듬들이 vector와 같이 사용될 수 있다. 다음 표는 이들중에서 보다 유용한것들만을 모아놓은 것이다. 예를 들어, vector에서의 최대값은 다음과 같이 알아낼 수 있다.
vector<int>::iterator where = max_element (vec_five.begin(), vec_five.end());cout << "maximum is " << *where << endl;
| 주어진 초기값으로 벡터를 채운다. | fill |
| 수열을 복사한다. | copy |
| 발생기(generator)가 생성한 값을 벡터에 집어넣는다. | generate |
| 조건을 만족하는 원소를 찾는다. | find |
| 연속적으로 중복된 원소를 찾는다. | adjacent_find |
| 벡터내에서 서브 시퀀스를 찾는다. | search |
| 최대 또는 최소 원소를 찾는다. | max_element, min_element |
| 원소의 순서를 뒤집는다. | reverse |
| 원소들을 새로운 값들로 대치한다. | replace |
| 가운데점을 중심으로 원소들을 순환시킨다. | rotate |
| 원소들을 두그룹으로 쪼갠다. | partition |
| 순열(permutation)을 생성한다. | next_permutation |
| 벡터내에서의 ... | inplace_merge |
| 벡터내의 원소들을 임의로 섞는다. | random_shuffle |
| 조건을 만족하는 원소들의 갯수를 센다. | count |
| 벡터로부터의 정보를 가지고 하나의 값을 만들어 낸다. | accumulate |
| 두 벡터의 내적을 구한다. | inner_product |
| 두벡터를 한쌍씩 비교하여 같은지를 검사한다. | equal |
| 사전식 비교 | lexicographical_compare |
| 벡터에 변환을 적용한다. | transform |
| 값들의 부분합을 구한다. | partial_sum |
| 이웃하는 값들의 차를 구한다. | adjacent_difference |
| 각 원소들에 대해 함수를 수행한다. | for_each |
비트값들의 벡터는 표준 라이브러리에서는 특별한 경우로 취급하여, 값들이 효과적으로 pack될 수 있다. 부울 벡터, vector<bool>을 위한 연산들은 일반 벡터 연산의 superset이고, 단지 구현이 더 효율적이다.
부울 벡터에서는 flip()이란 멤버 함수가 추가되었다. 호출되었을 때, 이 함수는 벡터의 모든 비트를 뒤집는다. 또한 부울 벡터는 내부값을 레퍼런스로 리턴하며, 이 레퍼런스에 대해서도 flip() 멤버 함수를 지원한다. 아래 코드의 세번째 줄이 이를 설명하고 있다.
vector<bool> bvec(27); bvec.flip(); // 모든 비트를 flip bvec[17].flip(); // 17번 비트를 flip
vector<bool>은 추가적으로 swap() 멤버 함수를 지원하는데, 이 함수는 한쌍의 레퍼런스가 가리키는 두개의 값을 서로 바꾼다.
bvec.swap(bvec[17], bvec[16]);
★ 주의: 위에서 설명한 멤버 함수 flip()과 swap()이 실제로 위와 같이 지원되는지 아직 확인하지 못했으니, 착오 없으시기 바랍니다. 현재 g++ 2.8.1에서는 swap()이 지원하지 않고 있고, 모든 비트를 flip하는 경우도 지원하지 않는 것 같습니다. 따라서, 이것이 표준에서 지원되지 않는 이유때문인지, g++이 아직 이부분을 구현에 반영하지 않은 것인지는 좀더 살펴봐야 하겠습니다. 이점에 관해 아시는 분은 연락주시면 고맙겠습니다.
이절에서 설명할 예제는 '에라토스테네스의 체'라고 하는 솟수를 찾는데 사용하는 아주 전통적인 알고리즘이다(제 또래 분들은 아마 예전 중학교 수학 시간에 배웠을 것임). 일단 솟수를 찾고자 하는 범위까지의 수들을 정수 vector에 담기로 한다. 이 알고리즘의 아이디어는 소수가 될 수 없는 수들을 하나씩 지워 나가면 (0으로 세팅), 가장 마지막에 남는 수들이 솟수가 된다는 것이다. 이를 위해서는 루프를 돌면서 각각의 값들이 1로 세팅된 수들의 배수인 것들을 하나씩 지워나가면 된다. 바깥쪽 루프가 끝나면 남아있는 수들이 솟수가 되는 것이다. 이 알고리즘의 프로그램은 다음과 같다.
int main(){ // 각 숫자들을 1로 모두 세팅한다. const int sievesize = 100; vector<int> sieve(sievesize, 1); // 1로 세팅된 값들 각각에 대해 이 수의 배수들을 0으로 세팅한다. for (int i = 2; i * i < sievesize; i++) if (sieve[i]) for (int j = i + i; j < sievesize; j += i) sieve[j] = 0; // 1로 세팅된 숫자들만 출력한다. for (int j = 2; j < sievesize; j++) if (sieve[j]) cout << j << " "; cout << endl;}| [펀글] MFC tip 10 (0) | 2008.09.24 |
|---|---|
| 채터링을 c로 짤려는데 잘안되네여.. (0) | 2008.09.15 |
| [STL] DEQUE (0) | 2008.09.10 |
| XML Programming with C++ (1) | 2008.08.31 |
| PIC16C84 (0) | 2008.08.29 |
■ deque의 능력
● 원소들을 컨테이너의 앞과 끝에 삽입및삭제하는 과정이 빠르다 (vector는 끝의 경우만 빠르다)
이 동작들은 “아모타이즈드” 상수 시간에 이루어진다
● deque의 내부 자료구조는 원소를 액세스하기 위해서 하나 이상의 간접성(indirection)을
이용하기 때문에, 원소의 액세스 시간과 반복자의 이동 시간이 약간 더 느리다
(분리된 메모리 블록을 이용하기 때문에)
● 반복자는 반드시 기존의 포인터 타입이 안라 스마트 포인터여야 한다.
왜냐하면, 다른 메모리 블록으로 이동을 할 수 있어야 하기 때문이다
● 만약 시스템에서 메모리 블록에 대한 사이즈의 제한값이 존재한다면, deque는 vector에 비해서
더 많은 원소를 가질 수 있다.왜냐하면,deque는 하나 이상의 메모리 블록을 사용하기 때문이다.
그러므로 max_size()는 vector에 비해서 더 큰 값을 반환할 것이다.
● deque는 용량과 재할당 같은 제어조건을 사용자에게 주지 않는다. 특별히 deque에서는 원소의
삽입과 삭제가 이루어지는 순간, 원소를 참조하고 있던 모든 포인터와 레퍼런스, 반복자들을
무효화시킨다(맨 앞부분과 맨 뒷부분에 삽입 및 제거를 하는 경우에는 예외이다).
그러나 deque의 재할당은 vector보다 효율적으로 이루어진다. 왜냐하면,
deque의 내부 자료구조의 특성상 deque는 재할당시에 모든 원소들을 복사할 필요가 없다.
● 메모리 블록은 더 이상 사용되지 않을 경우 해제된다. 그러므로 eque의 메모리 사이즈는
줄어들 수 있다(그러나 언제, 어떻게 이루어지는 지는 구현에 따라 다르다).
다음 사항은 vector와 동일하게 적용된다
● 컨테이너의 중간에 원소를 삽입 및 제거하는 동작은 시간을 필요로 한다. 왜냐하면, 삽입되거나
삭제된 원소 이후의원소들이 모두 이동하거나 공간이 부족할경우 새로운공간을 만들기때문이다.
● 반복자는 랜덤 액세스를 지원한다.
요약하자면, 다음과 같은 상황에서는 deque를 선호하는 것이 좋다.
● 컨테이너의 앞쪽과끝쪽으로 삽입과삭제가 이루어지는경우(이것은 queue 구조를위한경우이다)
● 컨테이너의 원소드을 참조하지 않는 경우
● 컨테이너가 더 이상 사용되지 않을 경우 메모리가 해제되기를 원할 경우
(표준에서는 언제 해제되는지에 대한 명시가 없다)
vector의 인터페이스와 deque의 인터페이스는 거의 유사하다. 따라서 vector의 사용법을 안다면 deque를 사용하는 것에는 별다른 어려움이 없다.
■ deque의 생성자와 소멸자 | |
동작 | 효과 |
deque<Elem> c | 원소 원이 빈 deque를 생성한다 |
deque<Elem> c1(c2) | 같은 타입의 다른 deque를 복사하여 생성한다(모든 원소들은 복사된다) |
deque<Elem> c(n) | 디폴트 생성자에 의해서 생성되는 n개의 원소와 함깨 deque를 생성한다 |
deque<Elem> c(n,elem) | elem 원소의 n개의 복사본으로 deque를 초기화하여 생성한다 |
deque<Elem> c(begn,elem) | [beg,end) 범위의 원소로 deque를 초기화하여 생성한다 |
c.~deque<Elem>() | 모든 원소들을 파괴하고 메모리를 해제한다 |
■ deque의 수정하지 않는 동작들 | |
동작 | 효과 |
c.size() | 실제 원소의 개수를 반환한다 |
c.empty() | 컨테이너가 비어있는지를 판단한다 (size()==0와 동일하나 더 빠르다). |
c.max_size() | 컨테이너가 가질 수 있는 최대 원소의 개수를 반환한다. |
c1 == c2 | c1과 c2가 같은지 판단한다 |
c1 != c2 | c1과 c2가 다른지 판단한다 ( !(c1==c2)와 동일하다 ). |
c1 < c2 | c1이 c2보다 작은지를 판단한다 |
c1 > c2 | c1이 c2보다 큰지를 판단한다( c2<c1과 동일하다 ). |
c1 <= c2 | c1이 c2보다 작거나 같은지를 판단한다 ( !(c2<c1)와 동일하다 ). |
c1 >= c2 | c1이 c2보다 크거나 같은지를 판단한다 ( !(c1<c2)와 동일하다 ). |
c.at(idx) | 인덱스가 idx인 원소를 반환한다 (만약 idx가 범위를 벗어났다면 범위 에러 예외를 발생시킨다) |
c[idx] | 인덱스가 idx인 원소를 반환한다(에러 검사를 하지 않는다) |
c.front() | 첫 번째 원소를 반환한다(원소가 있는지 검사하지 않는다) |
c.back() | 마지막 원소를 반환한다(원소가 있는지 검사하지 않는다) |
c.begin() | 첫 번째 원소를 가리키는 랜덤 액세스 반복자를 반환한다 |
c.end() | 맨 마지막 원소 뒤를 가리키는 랜덤 액세스 반복자를 반환한다 |
c.rbegin() | 역방향에서 첫 번째 원소의 역방향 반복자를 반환한다 |
c.rend() | 역방향에서 마지막 원소 뒤를 가리키는 역방향 반복자를 반환한다 |
■ deque의 수정하는 동작들 | |
동작 | 효과 |
c1 = c2 | c2의 모든 원소들을 c1에 할당한다 |
c.assign(n, elem) | elem 원소의 n개의 복사본을 할당한다 |
c.assign(beg, end) | [beg,end) 범위의 원소를 할당한다 |
c1.swap(c2) | c1과 c2의 데이터를 교체한다. |
swap(c1,c2) | 동일하다(전역 함수). |
c.insert(pos,elem) | 반복자 pos위치에 elem의 복사본을 삽입한다 그리고 새로운 원소의 위치를 반환한다 |
c.insert(pos,n,elem) | elem의 n개의 복사본을 반복자 pos 위치에 삽입한다. 반환값은 없다. |
c.insert(pos,beg,end) | [beg,end) 범위의 모든 원소들을 복사하여 반복자 pos 위치에 삽입한다. 반환값은 없다. |
c.push_back(elem) | 끝부분에 elem의 복사본을 추가한다. |
c.pop_back() | 마지막 원소를 제거한다(제거된 원소를 반환하지 않는다.) |
c.push_front(elem) | 앞부분에 elem의 복사본을 추가한다 |
c.pop_front() | 첫 번째 원소를 재거한다(제거된 원소를 반환하지 않는다). |
c.erase(pos) | 반복자 pos 워치의 원소를 제거한다. 그리고 다음 원소의 위치를 반환한다. |
c.erase(beg,end) | [beg,end)범위의 모든 원소들을 제거한다. 그리고 다음 원소의 위치를 반환 |
c.resize(num) | 원소의 개수를 num개로 변경한다 (만약 size()가 증가된다면, 새로운 원소들은 그들의 디폴트 생성자에 의해서 생성된다.) |
c.resize(num,elem) | 원소의 개수를 num개로 변경한다 (만약 size()가 증가된다면, 새로운 원소는 elem의 복사본이다). |
c.clear() | 모든 원소들을 제거한다(빈 컨테이너로 만든다). |
deque의 동작은 다음과 같은 경우에만 vector와 다르다
1. deque는 용량에 관한 함수들을 제공하지 않는다(capacity()와 reserve()).
2. deque는 앞부분과 끝부분에 직접적으로 원소를 추가, 삭제할 수 있는 함수를 제공한다
( push_front()와 pop_front() ).
다른 동작들은 vector와 동일하지다 다음과 같은 상황하에 대해서는 주의해야만 한다
1. at()을 제외한 모든 멤버 함수는 인덱스나 반복자가 유효하지 검사하지 않는다
2. 원소의 삽입 및 제거는 재할당을 유발한다. 그러므로 모든 삽입 및 제거 동작은 모든 포인터와
레퍼런스, deque의 다른 원소를 참조한는 반복자를 무효화시킨다. 그러나 맨앞부분과 뒷부분의
경우는 이에 해당하지 않는다. 이 경우에는 레퍼런스와 포인터는 유효하다.
그러나 반복자는 여전히 유효하지 않다.
| 채터링을 c로 짤려는데 잘안되네여.. (0) | 2008.09.15 |
|---|---|
| 5장: vector와 vector<bool> (0) | 2008.09.10 |
| XML Programming with C++ (1) | 2008.08.31 |
| PIC16C84 (0) | 2008.08.29 |
| Electronic combination lock with PIC (0) | 2008.08.29 |
C++ is a popular programming language for which many XML related efforts already exist. The aim of this article is to introduce and analyze the different options available when using C++ for your XML applications.
We will examine two things: the main APIs and strategies for parsing and manipulating XML in your C++ application, and the practical uses and tradeoffs of approaches to XML parsing.
To get the most from this article, a basic understanding of the C++ language is required. Static model diagrams are illustrated in UML: the diagrams used show mainly inheritance and simple relationships and may not require previous UML knowledge. Nevertheless, we provide a basic UML guide containing all you need to know in order to understand the examples.
Several toolkits and libraries have been produced for C++ based manipulation. Those toolkits mainly fall into two categories: event-driven processors and object model construction processors. We will examine both.
In an event-driven approach for processing XML data, a parser reads the data and notifies specialized handlers that undertake the desired actions. Note that here the term event-driven means a process that calls specific handlers when the contents of the XML document are encountered. For instance, calling endDocument() when the end of the XML document is found.
The various XML parser implementations differ in their application program interfaces. For example, one parser could notify a handler of the start of an element, passing it only the name of the element and then requiring another call for the handling of attributes. Another parser could notify a handler when it finds the same start-element tag and pass it not only the name of the element, but a list of the attributes and values of that element.
Another important difference between XML parsers is in which representation they use to pass data from the parser to the application: e.g. one parser could use an STL list of strings, while another could use a specially made class to hold attributes and values. The methods for handling a start-element tag with each approach would be very different and would certainly affect how you program them.
// Example: different ways of communicating data to handlers// STL based attribute passing// with an STL based event-driven handler a startElementHandler// method might look like this virtual void HypotheticalHandler::startElementHandler(const String name,const list<String> attributes) = 0; // Special Attribute List Class provided// With some event-driven APIs a special AttributeList object // containing attribute information// is used. This is the case with IBM's xml4c2 parser.virtual void DocumentHandler::startElement(const XMLCh* const name, AttributeList& attrs) = 0;
As you can see, the way processors notify applications about elements, attributes, character data, processing instructions and entities is parser-specific and can greatly influence the programming style behind the XML-related modules of your system.
Efforts to create a standard event-driven XML processing API have produced SAX (the Simple API for XML). A standard interface for SAX in C++ has not yet been developed. Nevertheless, the importance and growing use of SAX in C++ XML based applications is unquestionable, and makes it an important topic in our discussion.
In the next two sections, we examine the ideas behind both non-SAX and SAX-based event-driven approaches to parsing. For our examples, we will be using expatpp (C++ wrapper of James Clark's expat parser) and xml4c2 (IBM's C++ XML parser), respectively. IBM's parser will be re-released at the end of this year as "Xerces," part of the new Apache XML Project.
Expat is a C parser developed and maintained by James Clark. It is event-driven, in the sense that it calls handlers as parts of the document are encountered by the parser. User-defined functions can be registered as handlers.
Here is a sample of a typical expat use in C:
/* This is a simple demonstration of how to use expat. This programreads an XML document from standard input and writes a line with the name of each element to standard output, indenting child elements by one tab stop more than their parent element. [Taken from the standard expat distribution] */#include <stdio.h>#include "xmlparse.h"void startElement(void *userData, const char *name, const char **atts){ int i; int *depthPtr = userData; for (i = 0; i < *depthPtr; i++) putchar('\t'); puts("I found the element:"); puts(name); *depthPtr += 1;}void endElement(void *userData, const char *name){ int *depthPtr = userData; *depthPtr -= 1;}int main(){ char buf[BUFSIZ]; XML_Parser parser = XML_ParserCreate(NULL); int done; int depth = 0; XML_SetUserData(parser, &depth); XML_SetElementHandler(parser, startElement, endElement); do { size_t len = fread(buf, 1, sizeof(buf), stdin); done = len < sizeof(buf); if (!XML_Parse(parser, buf, len, done)) { fprintf(stderr, "%s at line %d\n", XML_ErrorString(XML_GetErrorCode(parser)), XML_GetCurrentLineNumber(parser)); return 1; } } while (!done); XML_ParserFree(parser); return 0;} This program simply shows the string "I found the element" followed by the element name for each element found. Note the existence of a void *userData parameter that expat uses to give you the possibility of managing your information across calls. In the previous example, the userData is employed to keep track of the indentation level that should be used when printing elements and attributes to the standard output.
Expat has many advantages: it is very fast and very portable. It is also under the GPL (the GNU General Public License), which means you can freely use and distribute it. But it is just plain C, so some strategy must be chosen in order to integrate it with your OO C++project.
One strategy would be simply to create global functions to register with expat. Those functions can receive a pointer to the data you want to modify while reading the file (e.g., a Count object that will store the number of characters in the file), and then all you have to do is register them with expat. This is a straightforward approach, but it brings several undesirable consequences into the picture:
It decreases the modularity of your program.
It makes your program less cohesive (i.e., related methods are not bundled together).
It may ruin your OO design on a fundamental level (e.g., XML serialization of your objects).
All of the above will probably result in a less-maintainable program with an error prone design. A better option would be to wrap expat using a C++ class that will encapsulate the C details and provide you with a clean list of methods that you can override to suit your particular needs. This is how wrappers like expatpp work.
Expatpp is a C++ wrapper for expat. It was developed by Andy Dent with this basic idea: the constructor of expatpp creates an instance of an expat parser, and registers dummy functions as handlers that call the corresponding expatpp override-able methods.
Some code will make things clearer:
// In its class definition, expatpp declares the callbacks// that it will register with the parser:static void startElementCallback(void *userData, const XML_Char*name, const XML_Char** atts);static void endElementCallback(void *userData, const XML_Char* name);static void charDataCallback(void *userData, const XML_Char* s, int len);//... and so on for the other handlers like// processingInstructionCallback// At the constructor, expatpp creates an expat parser and registers// the callbacksexpatpp::expatpp(){mParser = XML_ParserCreate(0);XML_SetUserData(mParser, this); //Note that the user data is//the object itselfXML_SetElementHandler(mParser, startElementCallback,endElementCallback);XML_SetCharacterDataHandler(mParser, charDataCallback);//... and so on with the other callbacks}// Now, for each callback there is a partner override-able member// likevirtual void startElement(const XML_Char* name, constXML_Char** atts){// Note that the default behavior is to do nothing. In your// derived class you can override this and for example print// the name of the element like// count << name;}// All a callback does is to call its partner methodinline void expatpp::startElementCallback(void *userData, const XML_Char* name,const XML_Char** atts){((expatpp*)userData)->startElement(name, atts);} // In runtime, when the parser begins calling the callback, the// appropriate method overridden in your derived class will be// called. For the complete code look at expatpp.[h|c]As you can see, the userData is used to maintain a pointer to your expatpp object. When the object is constructed, the callbacks are registered as handlers to expat. When parsing events occur, the handlers call the appropriate methods in the class. The default behavior of these methods is to do nothing, but you can override them for your own purposes.
The expatpp interface defines wrappers for all the methods in expat and includes the following members:
virtual void startElement(const XML_Char* name, const XML_Char** atts);virtual void endElement(const XML_Char* name);virtual void charData(const XML_Char *s, int len);virtual void processingInstruction(const XML_Char* target, const XML_Char* data);virtual void defaultHandler(const XML_Char *s, int len);virtual void unparsedEntityDecl(const XML_Char *entityName, const XML_Char* base, const XML_Char* systemId, const XML_Char* publicId, const XML_Char* notationName);virtual void notationDecl(const XML_Char* notationName, const XML_Char* base, const XML_Char* systemId, const XML_Char* publicId); // XML interfaces int XMLPARSEAPI XML_Parse (const char *s, int len, int isFinal); XML_Error XMLPARSEAPI XML_GetErrorCode(); int XMLPARSEAPI XML_GetCurrentLineNumber();
This interface defines a handler base for expatpp (look at the source code for details). Along with the example included below, it should be enough to get you started with expatpp in an XML project.
The following example uses expatpp to create a tree view of the elements of the document. Unlike the rest of the examples in this article, this particular program was constructed using Inprise C++ builder, and depends on it.
// We declare a handler that will be capable of// constructing the tree. In order to do so it will override// the startElement and endElement methods (the others can // be ignored)// [from myParser.h] class myParser : public dexpatpp{ private: TTreeView *mTreeView; // The tree view in which the elements will be shown TTreeNode *lastNode; public: inline myParser(TTreeView *treeToUse);inline void startElement(const XML_Char* name, const XML_Char** atts);inline void endElement(const XML_Char* name);}; // Now, for the implementation, all we have to do isinlinevoid myParser::startElement(const XML_Char* name, const XML_Char** atts){lastNode = mTreeView->Items->AddChild(lastNode, name);}// andinlinevoid myParser::endElement(const XML_Char* name){ lastNode = lastNode->Parent; }For the complete, and more verbosely documented, code, download this file: expatppExample.zip. When given an XML file, the application will produce something like this:

The same approach can be, and has been, used for wrapping other C parsers for use in C++ code. These other parsers include, most notably, the Gnome Project libxml parser by Daniel Veillard.
The next section will cover the Simple API for XML—SAX.
The Simple API for XML, SAX, is an event-driven API for parsing XML documents. It defines several handler classes that encapsulate the methods needed for specific tasks when parsing XML documents, such as external entity handling. As with other event-driven parsers, the basic process for the definition of an XML module in your project may be described by the following steps:
Subclass the required handler base classes. (In the previous section you did so only from expatpp; now you have more classes available for subclassing, which we will explore below.)
Override the desired methods.
Register your handler with the parser.
Start parsing.
These steps can be seen in the following example which prints an XML file, keeping track of the correct indentation. The interfaces used are explained further below. You can also look at the SAXCount example from IBM's xml4c2 documentation.
// We declare a handler of our own that will be capable of// remembering the correct indentation for "pretty"// printing the file. In order to do so we override// the startElement, characters and endElement handlers.// Take time to compare this solution to the expatpp solution to// the same problem (above)void PrettyPrint::startElement(const XMLCh* const name, AttributeList& attributes){ indent++; // A new element started, it should be indented one // level further than the current level int i; for(i = 0; i < indent; i++) outStrm << "\t"; outStrm << "<" << name; unsigned int len = attributes.getLength(); for (unsigned int i = 0; i < len; i++) { outStrm << " " << attributes.getName(i) << "=\"" << attributes.getValue(i) << "\""; } outStrm << ">";}void PrettyPrint::endElement(const XMLCh* const name){ int i; for(i = 0; i < indent; i++) outStrm << "\t"; outStrm << "</" << name << ">"; indent--;}void PrettyPrint::characters(const XMLCh* const chars, const unsigned int length){ for (unsigned int index = 0; index < length; index++) { switch (chars[index]) { case chAmpersand : outStrm << "&"; break; case chOpenAngle : outStrm << "<"; break; case chCloseAngle: outStrm << ">"; break; case chDoubleQuote : outStrm << """; break; default: outStrm << chars[index]; break; } }}void PrettyPrint::processingInstruction(const XMLCh* const target, const XMLCh* const data){ int i; for(i = 0; i < indent; i++) outStrm << "\t"; outStrm << "<?" << target; if (data) outStrm << " " << data; outStrm << "?>\n";} Download the full source here: saxExample.zip.
What makes SAX important is not the idea behind the parsing—the essence of the event-driven approach is the same as with expatpp or any other event-oriented parser—but the standardization of the interfaces and classes that are used to communicate with the application during the parsing process.
These classes and interfaces (abstract classes in C++) are divided thus:
Classes implemented by the parser: Parser, AttributeList, Locator (optional class used to track the location of an event)
Classes implemented by the application: DocumentHandler (very important—this is the one you will subclass in nearly all applications), ErrorHandler, DTDHandler, EntityResolver.
Standard SAX classes: InputSource, SAXException, SAXParseException and HandlerBase. (This might be your starting point in many applications since it inherits from all the handlers, providing default behavior for all non-overriden methods.)
SAX was initially developed for Java, but it has been ported to other languages like Python, Perl and C++. In C++, you have several representations and strategies to choose from when porting the original SAX API. Since there is no common C++ SAX interface, the different implementations might have some small, and not-so-small, differences.
In this article, we'll stick with IBM's xml4c2 SAX implementation. In order to write your own XML modules, you will need to inherit from the application classes of the API and override the methods you want to perform special actions.
Here is an overview of the handlers you will inherit from, a more complete documentation of them can be found with the xml4c2 distribution.
| Handler | Description |
|---|---|
| DocumentHandler | This is the main interface that SAX applications implement. It defines methods to let the parser inform the application about basic parsing events. In order to use it, the application should use a class that implements DocumentHandler and then register an instance with the parser, which will later feed it with the appropriate events. |
| ErrorHandler | This interface is provided in order to allow the SAX application to implement customized error handling. It is registered using the setErrorHandler method. The parser will then report all errors and warnings through this interface. |
| DTDHandler | Objects of a class that implement the DTDHandler interface receive information about notations and unparsed entities. They are registered using the parser's setDTDHandler method. |
| EntityResolver (less commonly used) | If the application needs to intercept any external entities before their inclusion, it must make use of a class that implements this interface registering it via the setEntityResolver method. Any external entities (including the external DTD subset and external parameter entities) will be reported through it. |
Note that by making use of the multiple inheritance support of C++, a user-defined handler can implement several of those functions (e.g., error handling and document handling).
// ... class MyHandler : public DocumentHandler, ErrorHandler // ... parser = new NonValidatingSAXParser; MyHandler* handler = new MyHandler(); parser->setDocumentHandler(handler); parser->setErrorHandler(handler);
The XML part of your application will probably take the following form:

If you are familiar with patterns, you will see this is similar to a simple Builder Pattern, i.e., we detach the XML responsibility from the client objects and delegate it to a collection of objects (the parser itself and your handlers) that will know how to incrementally construct some product. For a complete description of the Builder pattern see the book "Design Patterns" by Gamma et al. ("The Gang of Four.")
Note that this product can be expressed as another object, a simple return value, or even as some transformation of the attributes of your handler object.
This concludes the SAX review, and can serve as a starting point for your C++ XML modules. Please review the documentation of your chosen implementation for further examples. IBM's xml4c2 is recommended because of its comprehensive documentation.
The previous section presented the event-driven approach to handling XML documents. There is another option for the handling of XML documents: the "object model" approach. This approach is also known as the "tree based approach," and it is based on the idea of parsing the whole document and constructing an object representation of it in memory.
There is a standard language independent specification, written in OMG's IDL, for the constructed object model. It is called the Document Object Model, or DOM.
The next section presents the basic ideas behind the DOM, and the typical steps involved when writing a XML DOM-based module in your C++ application.
Expressing a document as a structure and making it available to the application is not new: all major browsers have done so for years in their own proprietary way. The important idea behind the XML DOM is that it standardizes the model to use when representing any XML document in memory. DOM-based C++ parsers produce a DOM representation of the document instead of informing the application when they encounter elements, attributes etc.
The Document Object Model is a language- and platform-independent interface that allows programs and scripts to dynamically access and update the content structure and style of documents. There is a core set of interfaces that every DOM 1.0-compliant implementation must provide. Here we concentrate on those core interfaces. Currently, anything in a document can be accessed using the DOM (1.0), except for the internal and external DTD subsets, for which no API currently exists.
The DOM, as the name implies, is an object model as opposed to a data model.
The object-oriented interfaces define the semantics of a structural model, independently of the implementation chosen for it. That means that DOM parser implementations are free to choose whatever internal representation they like, as long as they comply with the DOM interfaces. The next section will show the basic DOM core interfaces; then we will look at the steps you will use with the DOM approach.
The DOM level 1 core defines a basic set of interfaces that allow the manipulation of XML documents. It provides methods for the access and population of the document. These methods are encapsulated in two sets of interfaces: the fundamental core interfaces and the extended interfaces.
Here is a basic presentation of the main interfaces. For a complete description and all the methods, you will need to download a DOM library. Again, xml4c2 is a good choice because of its excellent documentation.
| Interface | Description |
|---|---|
| Node | This interface is the primary datatype for the entire Document Object Model. It represents a single node in the document tree. This is the base interface for everything in the model—therefore all objects implementing the Node interface expose the methods defined by it. One should be careful about this because some derivatives of node, like the text node, expose some Node methods they don't really support like "get children," which results in an exception since a text node cannot have children. |
| Document | Class to refer to XML Document nodes in the DOM. Conceptually, a DOM document node is the root of the document tree, and provides the primary access to the document's data. |
| DocumentFragment | DocumentFragment is a "lightweight" Document object. This object encapsulates a portion of the document, which is very useful in applications that need to rearrange or modify portions of the tree, for example an editor doing a cut/paste. Note that the fragment contained is not (necessarily or even often) a valid XML document. |
| Element | The majority of objects, apart from text, that one may find in the DOM Tree are DOM Element nodes. They represent elements in the document object model, and since they can have other Element nodes as children, their structure reflects the arrangement of the original XML document. |
| Other fundamental interfaces | The rest of the fundamental interfaces are: DOMImplementation, NodeList, NamedNodeMap, CharacterData, DOMException (which in IDL is not an interface but an exception), Attr, Text, Comment. Again, for more details on these, you are encouraged to download the complete documentation included in toolkits like xml4c2. |
The extended interfaces also form part of the core DOM. These interfaces are:
CDATASection
DocumentType
EntityReference
ProcessingInstruction
In order to get a complete view of the DOM, you should read the W3C recommendation. Nevertheless, here are some important points to keep in mind:
DOM Level 1 is strictly limited to those methods needed to represent and manipulate the document structure. At the time of the writing of this article DOM level 2 was not yet endorsed as a W3C Recommendation, and no C++ implementation was available, so for the sake of usability, I decided to focus on DOM level 1. Future DOM levels may provide:
Thread safety
Events
Control for rendering via stylesheets
Access control
Saving the DOM representation is left to the implementation
Changes to a Node are reflected in any NodeList or NamedNodeMap that refer to them. (This translates to the use of references or pointers in your C++ implementation.)
The DOM API is memory-management-philosophy independent (i.e., the recommendation does not specify any memory management policy). This is the responsibility of the implementation.
DOM defines the DOMString type in IDL as
typedef sequence<unsigned short> DOMString;
That is, a sequence of 16 bit characters using the UTF-16 encoding.
Even though some HTML processors may expect normalization to uppercase, the DOM bases its string matching in a purely case sensitive way. Nevertheless, it is admitted by the recommendation that some normalizations may occur before DOM construction.
In contrast to the role of the application during event-based parsing, the focus of the activity in a DOM-based application is post-parsing. The basic layout of an XML module using DOM might look something like this:

Here the main XML application class is no longer a handler but a manipulator of the DOM representation produced. Note that this is an important change of focus: your application's processing is no longer done at parsing time but rather in an extra module that will manipulate nodes.
The basic steps for the creation of your XML module would be:
Create and register handlers for errors and other implementation-dependent activities.
Create a DOM manipulator that will have the responsibility of (1) issuing parsing requests to the parser (2) manipulating the results of such requests.
Include the necessary manipulator/rest of the application interaction.
In order to complete the picture and give you a real idea of how all this fits together, the best thing to do is a complete walk-through of an example DOM-based implementation. Again, we consider an XML "pretty printer" as an example. A full example can be found in the DOMPrint sample distributed with IBM's xml4c2.
Note that for bigger projects, the correct encapsulation of the DOM processing activities in the above scheme is meant to keep your design clean and your program manageable.
The translation of the DOMPrint example to the DOM manipulator/DOM Parser/Rest of the application scheme is left as a simple exercise for the reader. In this case, all it requires is to take the methods of the original and encapsulate them in a class. So the main function can be something like:
#include "DOMBeautifier.h"static char* xmlFile = 0; // The name of the file to parse// --------------------------------------------------------------// Main - very simplified version -- for guidance purposes only.// Note that the main no longer takes responsibility of creating // the parser or printing the file. Try encapsulating that // in the DOMBeautifier class yourself, based on the original // DOM_Print (it's very easy an will give you a better feeling // of the library)// --------------------------------------------------------------int main(int argC, char* argV[]){ // Check command line and extract arguments. if (argC != 2) return 1; // The first parameter must be the file name xmlFile = argV[1]; // Now initialize the XML4C2 platform try { XMLPlatformUtils::Initialize(); } catch(const XMLException& toCatch) { return 1; } DomBeautifier *myBeautifier = new DomBeautifier(); if(myBeautifier->Beautify(xmlFile) == ERRORS){ return 2; } // Cleanup delete myBeautifier; return 0; }Now that we have seen both the event-based and DOM approaches to C++ XML document handling, we will examine the different considerations that will help you decide between each approach.
In this section, uses of and tradeoffs between the event-based and object model approaches will be discussed. In particular, three topics will be examined: having XML-aware objects that can be used as handlers, using factories to create/modify objects, and having a document-centered application. The section concludes with a list of C++ parsers and their suitability for the purposes outlined.
Note that the designs outlined here, while useful and used in real applications, are not necessarily the best ones for your project. They are provided only as a guide.
The first form of XML modules your application might use are simple XML aware classes designed to be registered in an event-driven parser. These classes are characterized not only by their handler nature, but by the self-containment of their activities. Their use doesn't usually compromise other classes, and the parsing of an XML document will often result in a change in their attributes or output operations.
These classes will take the following simple form:

Note that the handler base your handler inherits from is not necessarily HandlerBase from SAX; we use the term because every C++ event-driven parser will provide such base classes with a default behavior (HandlerBase in the case of xml4c2 or SAXParser, and expatpp itself in the case of expatpp).
Numerous examples of this approach are found with every parser, and they constitute the simplest, though very useful, form of XML use. Among the typical examples are the counting of elements in a document and the printing of each document element as it is found. Our SAX pretty printing example is good example of this approach.
These example activities could also be performed by traversing the object representation of the document, but they are typically done by the event-driven method because it does not require the memory expenditure that creating the object representation would.
There are lazy ways of creating the DOM in order to minimize the memory consumption, but even so in general terms, the event-driven approach must be used in these traversal cases for the sake of simplicity and good use of memory resources.
The next typical scenario is the definition of factory classes for the manipulation of other objects according to the information in the XML document. These classes will usually take the following form:

The first of such manipulations that comes to mind is serialization. The process of making an object persistent using XML is a very important issue that can be handled this way. The responsibility of saving the object as XML could also be in the object itself, but this approach—abstracting the responsibility for serialization—is often preferred.
Many other uses for this approach can be found. A simple example would be the manipulation of a collection of objects in accordance with XML-encoded instructions sent by a remote object, for example, a collection like:
map<name, long, less<string>> directory; // A simple STL directory using an associative container map // That will hold names(the keys) and phone numbers(the longs // that serve as values for that keys) // the third parameter less<string> is a function object // used to compare two keys.
could be manipulated by a remote object by sending messages like
<changeNumber name="Borges">5716124469</changeNumber>
to our factory that would translate them to:
directory["Borges"] = 5716124469;
Again, as in the simpler handlers described above, the preferred approach for these factories is the event-driven one, since it doesn't involve the cost of keeping the document in memory.
Of course, there are many special cases that must be considered. Take the case of an object that must answer questions from other objects about a particular document (like "is there any element named H1?"). In this case a tradeoff between memory consumption and speed takes place, since both a DOM and an event-driven approach could be used. The first involves more memory consumption but will greatly speed the searches of specific elements in the document. The second will consume no memory representing the document but will require a O(n) complexity over the XML document on disk for each search. The final decision will have to take into consideration the amount of requests, the size of the documents, and the amount of available resources.
So far, we have reviewed two mainly event-driven uses. In the next section we will explore cases where DOM is a more natural option.
The uses of the DOM can be very varied, such as exposing an object model of the document in a browser so an extension language can be used to manipulate the document. We will concentrate on a general case: the use of DOM as the model in a Model-View-Controller scheme.
Basically, the MVC defines a structure where there is an underlying model, several views that reflect the state of the model, and a controller that receives requests to change the model. It also ensures that these changes are reported to the views.

This is the case in many document-centered applications. For example, take a simple application that reads a document containing a memo like this:
<?xml version="1.0"?> <header> <to>Panda</to> <from>Le roi sanche</from> </header>
...and shows it to the user allowing it to be edited and written back to a file.
This, like any other application that needs to manipulate an object representation of the document itself as a base model, is perfect for DOM use.
Refinements to the model of constructing the tree and modifying the DOM via direct calls to the API can be used. Real life view objects can issue command objects that include the document fragment that is the target of the change (instead of changing the DOM directly). Also, several strategies to avoid loading the whole document at once could be applied.
Nevertheless, the basic idea remains what our simple example tries to show: whenever you need to manipulate the document directly as your model (instead of constructed domain-specific objects), DOM constitutes the natural choice.
We finish this section by presenting a list of commonly used C++ parsers and their basic information. (For performance comparisons, please refer to Benchmarking XML Parsers.)
| Parser | DOM Support | SAX Support | Platforms supported | Validation support | Download from |
|---|---|---|---|---|---|
| libxml | YES | YES | Linux, Win32 (possibly many others) | YES | ftp://rpmfind.net |
| expat (C) | NO | NO | Win32, Unix, and practically everywhere a modern C compiler exists. | NO | ftp://ftp.jclark.com |
| expatpp (only the wrapper, without extensions) | NO | NO | Win32, Linux, Mac (and many untested others) | NO | ftp://ftp.highway1.com |
| xml4c2 | YES | YES | IBM platforms: AIX 4.1.4 and higher, Win32 (MSVC 5.0, 6.0 compilers), Solaris 2.6, HP-UX B10.2 (aCC and CC), HP-UX B11 (aCC and CC), Linux | YES | www.alphaworks.ibm.com |
As you can see, C++ is well suited for XML processing in terms of availability, size and complexity of code, conformance, and even to a great extent, portability—not to mention performance. There is nothing especially better about using other languages like Java for XML programming.
All languages have strengths and weaknesses that should be taken into consideration when choosing the language to use for your project. It may be true that C++ has a steeper learning curve, and perhaps C++ programmers can be a little harder to find, but those considerations have nothing to do with C++'s ability to process XML. Great care should be taken when facing marketing hype about supposedly "perfect marriages" between a language and a specific technology. XML is no exception.
XML.com Copyright © 1998-2006 O'Reilly Media, Inc.
| 5장: vector와 vector<bool> (0) | 2008.09.10 |
|---|---|
| [STL] DEQUE (0) | 2008.09.10 |
| PIC16C84 (0) | 2008.08.29 |
| Electronic combination lock with PIC (0) | 2008.08.29 |
| 키 바운싱 & 채터링 제거하기 (0) | 2008.08.27 |
PIC16C84pic16F84를 이용해서 이것저것만드는, pic16F84를 갖고 놀기 위해서는 PIC writer 가 필요합니다. PIC16F84 같은 컨트롤러는 아주 간단하고 쉽습니다. PIC writer 는 인터넷에서 주문하시면 됩니다. 많은 분들이 구입하실꺼라면 공동구매하심 싸게 될지도... 방학이 시작되고 제가 기존에 하는일이 마무리되면 Chap. 1 이 시작될겁니다. Chap. 1 What is the "PIC16C84" ???일단 MicroController 가 뭔지부터 말해야겠죠. 그냥 하나의 컴퓨터라고 보시면 됩니다. 즉, 모니터 빼고 나머지부분... 메인보드를 하나의 칩으로 만든겁니다. 물론 작은만큼 여러 가지 제약이 따릅니다. 입출력 핀의 갯수, 내부 롬의 크기...... BUT!! 작다고 성능이 구리다는 것은 절대아닙니다!! 그럼 마이크로컨트롤러가 무엇인가... 그러니깐, 이런 것들을 프로그래밍한후 PIC writer 로 집어넣으면 그대로 동작한다는 겁니다. - 결국 병렬포트 제어와 별 다를 게 없습니다. portable 하다는 점외에는.. <PIC16C84 의 다리이름>
16F84 라는 것이 있습니다. 16C84는 EPROM 이라서 한번만 쓰면 끝인데 반해, <16C84 의 내부> 1KByte 의 롬 : 1KByte정도의 프로그램이 들어갑니다. 1-1 Register file중요한걸 빼먹었더군요.
< 특수기능 레지스터 >
Chap.2 PIC AssemblyChap.1에서 적어놓은 하드웨어를 주물럭거리기 위한 소프트웨어입니다. PIC 프로그래밍에는 C언어와 BASIC, 그리고, 어셈블리가 가능합니다. 물론 C나 베이직이 쓰기에 편하겠지만, 하드웨어를 직접 건드리는데는 어셈블리를 따라갈 수 없죠. 어셈블리에 약한 분들은 이번기회에 공부해두시면 앞으로 많은 도움이 될 것으로 믿습니다. PIC 에서 쓰이는 어셈블리는 일반 MS-DOS라든지 MS-WINDOW에서 쓰이는 어셈블리와 모양이 좀 다릅니다. 이점을 유의해 주시고.... 아래에 나오는 명령어는 모두 37개입니다. 당장 모두 외워 버려도 상관은 없지만... 만일 보통레벨의 분들이라면 외우지 않길 권장합니다. <참고> FSR 은 INDF 레지스터와 함께 간접 주소지정에 쓰입니다. <예>MOVLW 20H : W레지스터에 20H 넣음.
|
그래퍼님(Email : acmaskm@hotmail.com )께서 올려주셨습니다.
거듭 감사의 인사를 드리면서....
아래를 클릭하세요~!
control.new21.org/pic/grapher/index.html
[출처] PIC16F84 기초 (32_『LinuX』『EmbeddeD』__33) |작성자 애버
| [STL] DEQUE (0) | 2008.09.10 |
|---|---|
| XML Programming with C++ (1) | 2008.08.31 |
| Electronic combination lock with PIC (0) | 2008.08.29 |
| 키 바운싱 & 채터링 제거하기 (0) | 2008.08.27 |
| PIC의 활용 (PIC16F84, pic16f877) (0) | 2008.08.27 |
version 2, 023 - 2001/10/22 P16F84
version 2, 024 - 2004/10/04 P16F628
version 2, 025 - 2004/10/16 P16F628
designed by Peter JAKAB
NOTE for beginners: PICs are general purpose microcontrollers which have to be programmed before you can use them in the actual circuit! Check out this link to learn more.
 You can find part of this page translated to French at PC-Electronique
You can find part of this page translated to French at PC-Electronique
This is my electronic combination lock to use with an outdoor gate. The functionality is implemented in software. It turns on a relay (usually to open a door) for a few seconds if someone enters the valid code. This relay can operate a power-to-open type electric strike with a shorting contact or a power-to-hold type electromagnetic lock with a breaking contact (we need the relay because these locks usually work with AC, not DC). The code can be changed any time after entering the current code.
Current consumption of the circuit is low, because the PIC sleeps most of the time, and wakes up only for processing key presses. If you don't have a crystal, you can use the RC oscillator of the 16F84 as well, just check the PIC datasheets for details on oscillator configurations.
you have three choices of lock versions:
v2-023: written for P16F84
v2-024: adapted to P16F628
v2-025: LCD version, written for P16F628
These versions share many features in common, the differences are detailed below.
type in the correct code and use # as 'enter'. The initial code is 1234 after programming the un-modified HEX file. You could activate the output with typing in:
1 2 3 4 #
* is used to change the code. Type in the actual code then press *. If you didn't miss the actual code, the code change indicator LED will light up. Then type in the new code twice. Eg:
1 2 3 4 * 1 9 9 8 # 1 9 9 8 #
will change the code to 1998. The code changes immediately and permanently after typing the new code twice. If you miss entering the new code twice, the original code is kept.
Essentially, all software versions work the same. You can download and customize the source code for the version you choose. The first few lines of the code contain definitions of changeable parameters. If you are lazy, you can simply download the HEX files already compiled with default values. The definitions:
mhz EQU D'4' | this value is used for delay calibration. Of course, the code will run with different speed hardware as well, but faster or slower than intended. |
pulsewidth EQU 'D'150' | this value is used to set the delay of the output pulse. To calculate the delay in seconds, use pulsewidth * 20 ms |
clen EQU 4 | this value sets the length of the code. The length is always fixed, and you can set it much higher, until you have available RAM on the chip |
More details on the source code can be found here.
The keypad is actually a collection of push-buttons, organized into a matrix. It looks like this:
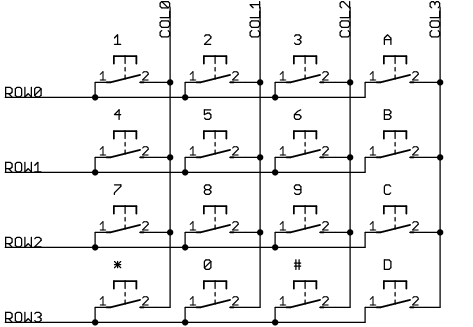
| COL0 | COL1 | COL2 | COL3 | |
| ROW0 | 1 | 2 | 3 | A |
| ROW1 | 4 | 5 | 6 | B |
| ROW2 | 7 | 8 | 9 | C |
| ROW3 | * | 0 | # | D |
If you have a different layout keypad, you can change the definition of the buttons (keytable) in the source code. The keytable contains four lines, each consisting of four characters:
dt "123a"dt "456b"dt "789c"dt "*0#d" |
You can use a 3x4 keypad or a 4x4 keypad. The advantage of the bigger keypad is that you can use the extra letters in codes. Connect the keypad wires to the lock by the labels (ROW0 to ROW0, COL0 to COL0, and so on). In case of using a 3x4 keypad, simply leave the COL3 input unconnected, no other modification is required. If you don't have a keypad, you can even wire one from push-buttons.
Use a power source with DC output between 8 and 30 volts, min 200 mA (or higher, depending on your relay current) to power the lock.
The relay specifications are not given here, because you can choose from many. Choose the relay voltage based on your incoming voltage. If you use 12VDC to power your lock, choose a 12V DC relay. Choose the relay switch ratings based on what you intend to switch with it. For an electric strike, use one capable of switching at least 2A/24V.
The component labeled 'BUZZER' is a passive ceramic piezo sounder. Do not use buzzers with internal (sound generator) electronics and/or with low-impedance speaker coils in it.
If you are stuck with a problem, please check the FAQ first.
Q: I don't want anyone to change the code. What should I do?
A: replace the '*' key in the keytable to '#'.
A: place the 3rd column of your keypad inside the box containing the PCB and change the keytable so as only the 3rd column contains the key '*'
Q: I lost the code for the lock. What should I do?
A: Re-program the PIC chip with the latest HEX file you used. The code will be reset to the value in the HEX file
A: read out the contents of the PIC with a programmer. You can find the actual code stored in the DATA EEPROM. Depending on the programmer software, the code can be modified and written back as well
Q: Is there a way to make this design work as an on/off switch (toggle) instead of a momentary switch? In detail, enter code to turn a switch on, enter the code again to turn the switch off
A: yes. The modified 16F84 code is downloadable here, name cl2b.asm
Q: The combination lock seems to work (it beeps once for every keypress), but it doesn't operate the relay!
A1: There can be a problem with operating your relay. To check, disconnect resistor from pin#8 (RB2) and touch it to the VDD (pin#14). If it does not operate the relay, check your transistor and the diode polarity. Measure the output of pin#8 (RB2) when you entered the correct code. It should change to +5VDC for the preset time interval then back to 0VDC
A2: you possibly misconnected some row/column lines so incorrect keycodes are generated. Eg, if you swap col0 and col1 wires, and press the keys 1 2 3 4, it gets interpreted as 2 1 3 5
Q: I don't have a 22pF capacitor. Can I use another value?
A: yes, any value between 10-25pF should work
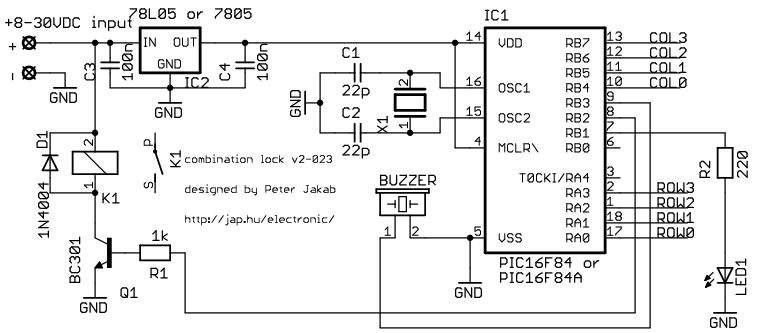
| description | written by | download |
| source code and HEX file with default settings (10 MHz) | Peter JAKAB | cl2.asm cl2.hex |
| HEX file with default settings for 4MHz | Peter JAKAB | cl2-04.hex |
| details of the source code internals | Peter JAKAB | combination_lock-alg.txt |
| experimental source and HEX file modified for toggle (ON/OFF) relay operation | Peter JAKAB | cl2b.asm cl2b.hex |
| experimental source modified to accept 8 different 6-digit codes | Alan Carvalho de Assis | cl2c.asm |
| experimental source and HEX file modified to accept two different 6-digit codes for activating two pulse outputs the second output is RB0 | Melvic S. Punzalan | cl2d.asm cl2d.hex |
| part number | description |
| IC1 | PIC16F84-10 or PIC16F84A - Microchip microcontroller, pre-programmed |
| IC2 | 78L05 or 7805 - 5V output voltage regulator |
| Q1 | BC301 or similar npn bipolar transistor, Ic(min)=500 mA |
| D1 | 1N4001, 1N4004 or 1N4007 diode |
| LED1 | any color LED or 3mm green LED |
| R1 | 1 kohm 1/4W resistor |
| R2 | 220 ohm 1/4W resistor |
| C1 | 22 pF ceramic capacitor |
| C2 | 22 pF ceramic capacitor |
| C3 | 100 nF ceramic capacitor |
| C4 | 100 nF ceramic capacitor |
| X1 | 10MHz or 4MHz crystal |
| BUZZER | ceramic piezo sounder (also called 'piezo diaphragm', 'piezo audio transducer', 'piezo audio indicator') |
| keypad | 3x4 or 4x4 matrix keypad |
| K1 | relay, see text for specifications |
| misc | power supply with 8-30V DC output - suggested voltage is 12VDC connectors for the power supply and the keypad Printed Circuit Board (PCB), strip board or bread-board flexible wires for connecting relay, LED, buzzer, power supply, keypad housing for the electronics |
Please note that the component numbering and connector pin-out on the PCB won't match the schematic!
| PCB name | Postscript | |
| standard PCB | copper stuffing | copper stuffing |
| PCB with power supply | copper stuffing | copper stuffing |
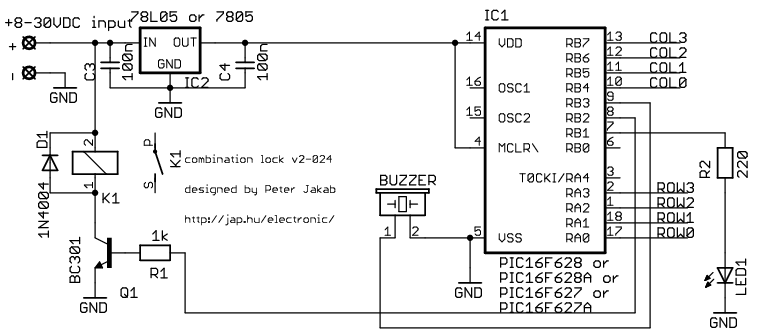
| description | written by | download |
| source code and HEX file for the 16F627/8 with default settings | Peter JAKAB | cl2-024.asm cl2-024.hex |
| part number | description |
| IC1 | PIC16F627 or PIC16F628 or PIC16F627A or PIC16F628A - Microchip microcontroller, pre-programmed |
| IC2 | 78L05 or 7805 - 5V output voltage regulator |
| Q1 | BC301 or similar npn bipolar transistor, Ic(min)=500 mA |
| D1 | 1N4001, 1N4004 or 1N4007 diode |
| LED1 | any color LED or 3mm green LED |
| R1 | 1 kohm 1/4W resistor |
| R2 | 220 ohm 1/4W resistor |
| C3 | 100 nF ceramic capacitor |
| C4 | 100 nF ceramic capacitor |
| BUZZER | ceramic piezo sounder (also called 'piezo diaphragm', 'piezo audio transducer', 'piezo audio indicator') |
| keypad | 3x4 or 4x4 matrix keypad |
| K1 | relay, see text for specifications |
| misc | power supply with 8-30V DC output - suggested voltage is 12VDC connectors for the power supply and the keypad Printed Circuit Board (PCB), strip board or bread-board flexible wires for connecting relay, LED, buzzer, power supply, keypad housing for the electronics |
On popular request, I wrote the code for adding a 2x16 character HD44780-compatible LCD to this project.
In addition to the standard definitions, you may want to change these variables:
#define HIDDEN_CODE '*' | this is the definition of what you see on the LCD instead of the digits (default is asterisk). If you delete this line, the digits are shown as entered |
msg_line EQU 0x80 | this value contains the LCD position for messages. By default it contains the address of the first LCD line (documented in the LCD datasheet) |
code_line EQU 0xc0 | this value contains the LCD position for code entry. By default it contains the address of the second LCD line (documented in the LCD datasheet) |
This is not the whole schematic, you also need the serial LCD interface, which connects to the 6-pin connector 'serial LCD'.
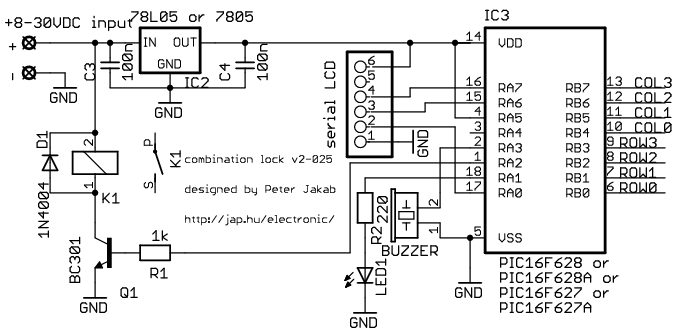
| description | written by | download |
| source code and HEX file with default settings | Peter JAKAB | cl2-025.zip cl2-025.hex |
| HEX file, show entered digits in clear | Peter JAKAB | cl2-025b.hex |
The parts for the LCD interface are not included in this list.
| part number | description |
| IC1 | PIC16F627 or PIC16F628 or PIC16F627A or PIC16F628A - Microchip microcontroller, pre-programmed |
| IC2 | 78L05 or 7805 - 5V output voltage regulator |
| Q1 | BC301 or similar npn bipolar transistor, Ic(min)=500 mA |
| D1 | 1N4001, 1N4004 or 1N4007 diode |
| LED1 | any color LED or 3mm green LED |
| R1 | 1 kohm 1/4W resistor |
| R2 | 220 ohm 1/4W resistor |
| C3 | 100 nF ceramic capacitor |
| C4 | 100 nF ceramic capacitor |
| BUZZER | ceramic piezo sounder (also called 'piezo diaphragm', 'piezo audio transducer', 'piezo audio indicator') |
| keypad | 3x4 or 4x4 matrix keypad |
| K1 | relay, see text for specifications |
| lcdif | serial LCD interface: an HD44780-compatibe 2x16 char LCD and some more electronics |
| lcdconn | 6-pin header for connecting the LCD interface |
| misc | power supply with 8-30V DC output - suggested voltage is 12VDC connectors for the power supply and the keypad Printed Circuit Board (PCB), strip board or bread-board flexible wires for connecting relay, LED, buzzer, power supply, keypad housing for the electronics |
| XML Programming with C++ (1) | 2008.08.31 |
|---|---|
| PIC16C84 (0) | 2008.08.29 |
| 키 바운싱 & 채터링 제거하기 (0) | 2008.08.27 |
| PIC의 활용 (PIC16F84, pic16f877) (0) | 2008.08.27 |
| MFC 주요 멤버 변수와 함수 (0) | 2008.08.26 |
Bouncing
스위치에서 필연적으로 생기는 현상으로, 스위치에 내장된 스프링과 같은 탄성체가
접점에서 떨어질때 자신이 가진 탄성과 접촉면의 불균일성 때문에 농구공 튀듯이
부르르 떠는 현상, 결과적으로 여러번 개폐가 수초내에 생기는 것이다.
Chattering
이것 또한 스위치 필연적으로 생기는 현상으로, 이것역시 접점의 접촉면 불균일성
때문에 On/Off가 반복되다가 안정되는 현상이다 공학적인 면에서 봤을땐, 바운싱과
채터링을 거의 동일한 현상이라고 간주 한다,
내가 생각했을때는, 바운싱은 스위치의 신호가 떠는 현상만을 일컫는 것이고,
채터링은 바운싱 +입력 신호 검출이라 생각된다.
여기서 입력 신호 검출이란, 사용자가 스위치를 한번 눌렀을때, 이 신호를 잡아내는 MCU등은 워낙 빠른 속도로 동작하기
때문에 사용자가 잠깐 누르는 시간 동안에도 몇번씩 신호을 읽어 오게 된다. 그래서 스위치를 한번 눌렀음에도 불구하고 스위치를 여러번 누른것과 같은 효과가 생기는것이다.
이것을 통틀어서 채터링이 생긴다고 하는것 같다.
해결책
보통 2가지 방법으로 위 두가지 현상을 해결하는데 첫째는 하드웨어적인 해결이고
두번째는 소프트웨어적인 해결이다.
소프트웨어적인 해결만 생각해 보자
채터링 현상을 잡아 내기 위해선, 스위치가 눌러 졌을때와 스위치를 눌렀다 떼었을때를 생각 해보야 한다.
첫째, 눌렀을때 바로 스위치가 연결되는것이 아니고 수cycle동안 미세하게 신호가 떨리게 된다.
그래서 이 구간을 벗어나게 해야 되는데,
해결책으론 처음 눌렀을때 스위치 값과 수 cycle의 시간이 지난후에
스위치 값을 다시 읽어 처음에 읽은 값과 비교를 해보는것이다.
그래서 비교를 해서 동일 하다면 스위치 입력으로 간주하는것이다. 이와 비슷한 방법으로 cpu의 타이머 인터럽트 세팅해서 스위치가 눌러 졌을때 스위치 값을 한번 읽고,
타이머 동안의 시간이 지난후 다시 스위치 값을 읽어 오는 방법이 있겠다.
둘째로, 눌렀다 떼었을때다.
이부분이 사실 중요하다 볼수있다. 하룻동안 생각을 잘못해서 본인이 스위치 값만 읽어와서 0과 같으면 스위치를 떼었다고
간 주하고 프로그래밍을 했었다. 완전 잘못된 것이었다.
스위치가 눌린 상태든 떨어진 상태든지, 스위치가 열고 닫히는 구간에서 신호가 변하게 된다. 이것을 잡아 내면 되는것이다.
즉, 처음에 신호를 읽어오고 수cycle뒤에 스위치 값을 읽어와서
먼저 읽은 신호와 비교를 해서 신호가 다르면 스위치가 떨어졌다고 생각하면 되는것이다
| PIC16C84 (0) | 2008.08.29 |
|---|---|
| Electronic combination lock with PIC (0) | 2008.08.29 |
| PIC의 활용 (PIC16F84, pic16f877) (0) | 2008.08.27 |
| MFC 주요 멤버 변수와 함수 (0) | 2008.08.26 |
| C++ 에서의 메모리 할당 (0) | 2008.08.12 |
 <PIC16F84 - pictured by Jin>
<PIC16F84 - pictured by Jin>